

Retrieval Augmented Generation (RAG) is an AI technique for getting more tailored responses from a foundation model, without the need for training or fine-tuning a model from scratch. Large Language Models, such as Meta’s LLaMA 2, provide high quality responses to prompts based on the general body of knowledge that they were trained on, but perform much better in domain-specific applications with model fine-tuning or RAG.
Training or fine-tuning an AI model requires a large volume of training data, the model weights (in the case of an already existing model), and a great deal of computational power from the most powerful GPUs such as the NVIDIA H100 or A100. Because the fine-tuning process is so computationally intensive, it is more suited for AI applications where the body of knowledge changes only occasionally, and low latency, high throughput inference is the most important consideration.
RAG is more suited to AI applications where a higher latency when using the model is acceptable, as the model must first “retrieve” the data from a vector database prior to inference. But because no pre-training is required, RAG is an ideal approach to having an AI model take into consideration fast-changing data that is regularly loaded into the data warehouse, or streamed in from an external data source via a data pipeline. RAG can also be considered as an alternative to fine-tuning an AI model, where an organization is just beginning to evaluate the potential of adopting AI LLMs, and the needs of the applications are anticipated to rapidly change.
Model Fine-Tuning vs. Retrieval Augmented Generation (RAG)
The best way to illustrate the relative strengths and differences between model fine-tuning and RAG is by for example, taking into consideration a hypothetical “legal AI” application. The AI techniques can be used in conjunction with each other, and are not mutually exclusive. Statutes only change periodically when lawmakers pass new legislation or amend existing laws, but case law is updated whenever a judge makes a new ruling on a case before the courts. It might make more sense to fine-tune an AI model based on the jurisdiction’s statutes, but use RAG to regularly import in the case law that is constantly changing.
An excellent example of an AI application where RAG might be used standalone, is an AI assistant for sales representatives who need to determine which customers have the biggest propensity for purchasing certain products based on previous sales history.
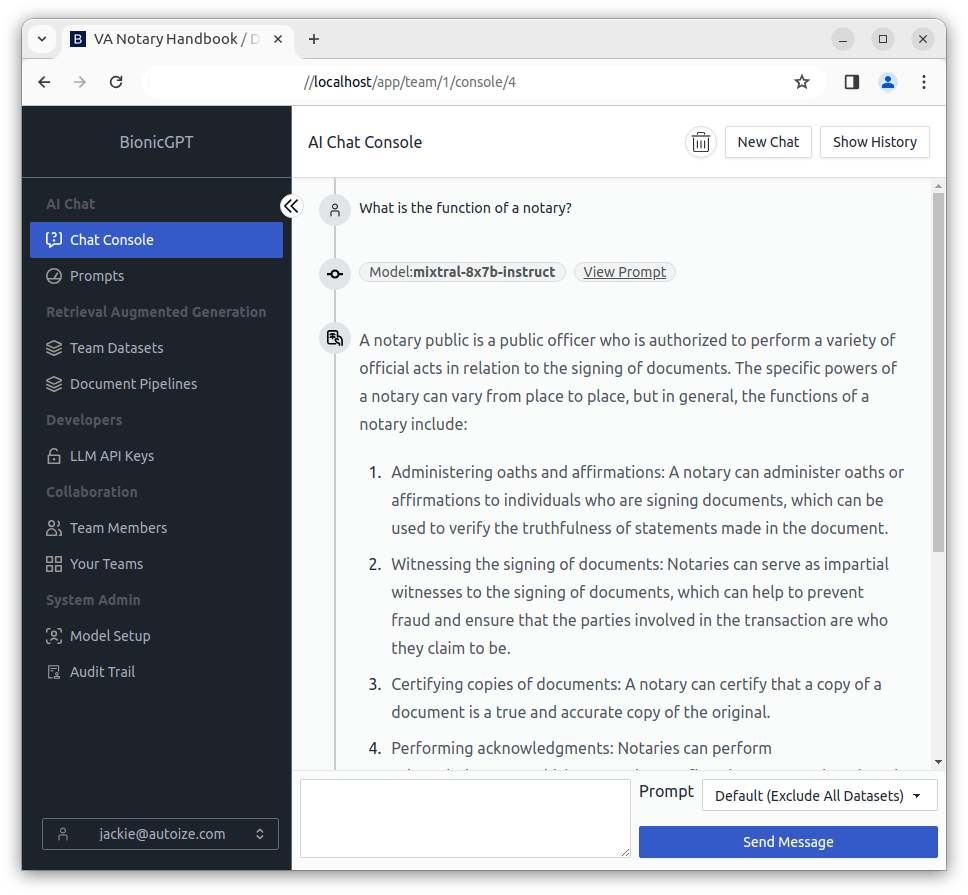
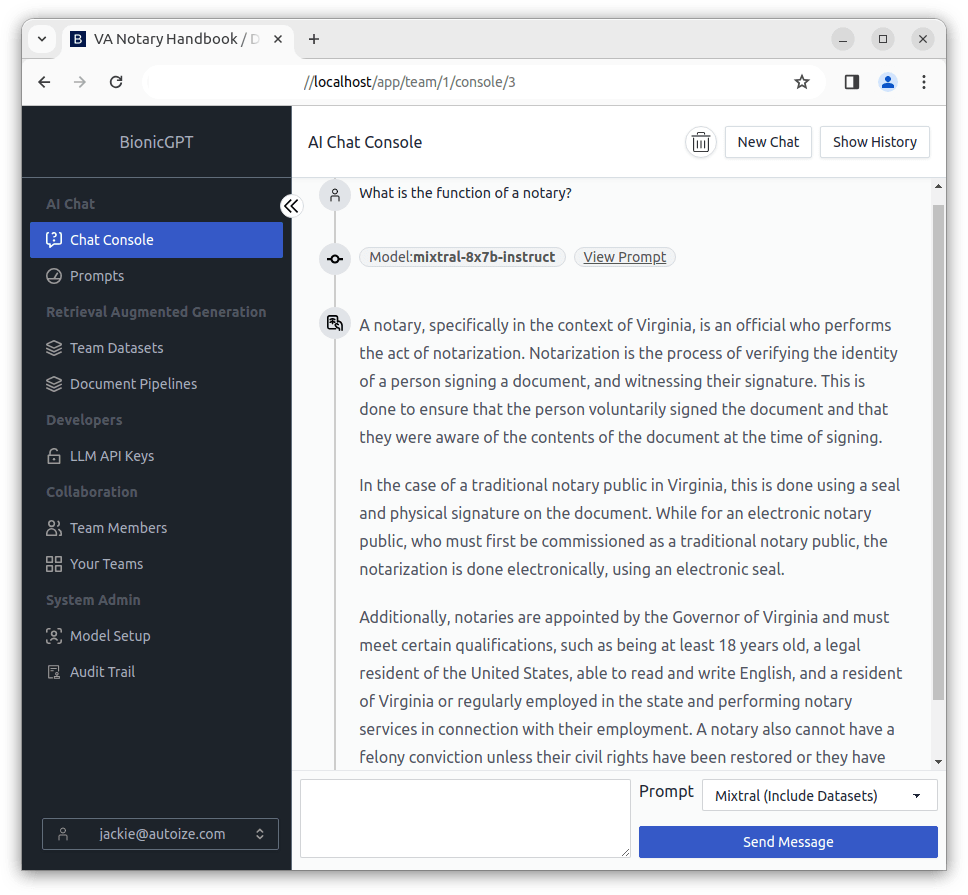
In the screenshots below, we compare the performance of the Mixtral 8x7b model with versus without using the Virginia Notary Handbook as an embedded data set. You can clearly see that the AI responds with a much more useful answer that is tailored to the legal requirements of the particular jurisdiction, the State of Virginia, when embeddings are used for RAG.
Prompt/Response without Retrieval Augmented Generation (RAG)
Prompt/Response with Retrieval Augmented Generation (RAG)
There are two main types of models which are useful in the context of a Large Language Model based application, such as a ChatGPT-style interface: Large Language Models (LLMs) and Embedding Models. You are probably already familiar with LLMs, which perform inference and provide a response based on a prompt. Embedding models convert semi-structured or unstructured data into a graph or vector data type that can be consumed by an LLM. An example of an LLM is LLaMA 2, and an example of an embedding model is Unstructured.io or BAAI General Embedding (BGE). The first step for performing RAG is uploading data such as PDF files, Word documents, or Excel sheets and processing them with an embeddings model. The vector data generated by the embedding model is written to a vector database such as Neo4j or PostgreSQL with the pgVector extension.
When a user makes a natural language prompt to the model via the chat interface, the AI application will retrieve the specified dataset(s) from the vector database so that the LLM takes the embedded data into account when reasoning and inferencing.
Reference Architecuture: RAG AI Application
Our AI infrastructure architects have prepared a reference architecture for a RAG AI Application consisting of a chat frontend (application), a Postgres database for the application, a Postgres DB for the vector embeddings, an embedding model, and an LLM.
- Chat Frontend (Bionic-GPT): End users interact with chatbot through a web-based interface.
- Application Database (Postgres): User table and conversations are stored here.
- Embedding Database (Postgres with pgVector): Datasets (PDFs, Word docs, Excel sheets) processed by the embedding model are stored here in vector format.
- Embedding Model: Unstructured.io or Text Embeddings Inference with BAAI/BGE model
- Large Language Model: LLaMA 2 or other open source LLM
- Architecture: ChatGPT-style Interface with AI Worker Nodes (GPUs)
Download PDF: ChatGPT-style Interface with AI Worker Nodes (GPUs)
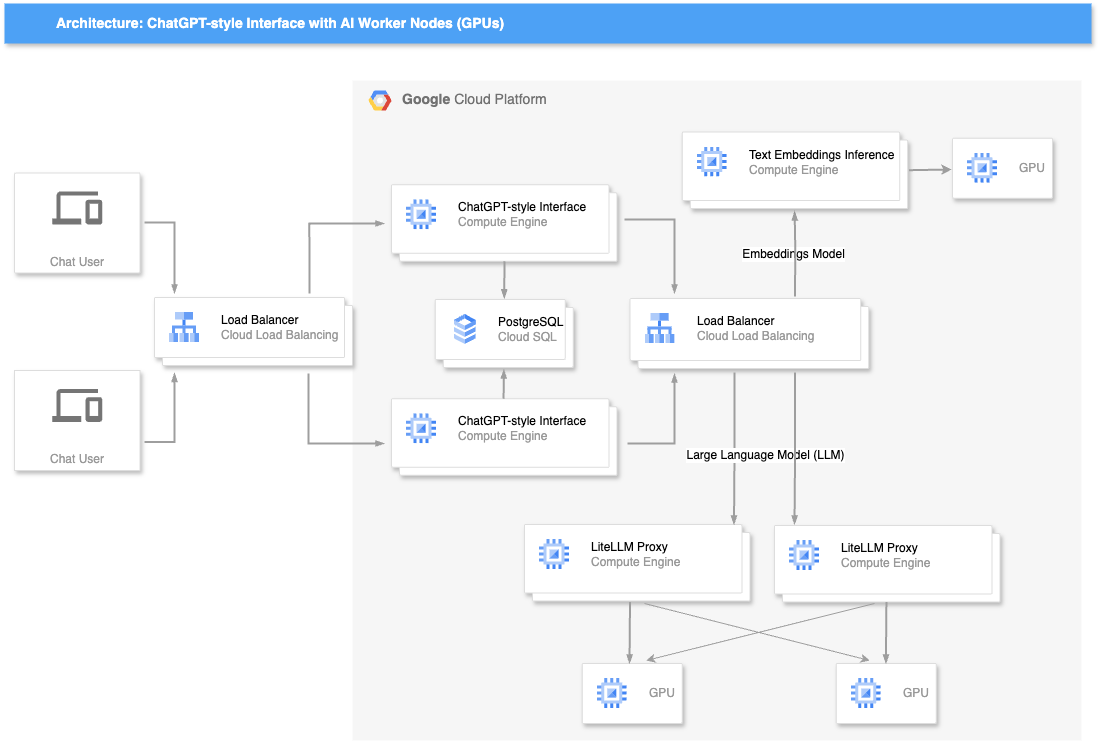
For scalability and availability, the application is deployed behind an external load balancer, and the LLM and embedding model is behind an internal load balancer. If you wanted to use external model endpoints instead of deploying your own GPUs, the GPUs can be substituted by hosted endpoints at a provider such as Vertex AI, Bedrock, or OctoAI. You might prefer to use a provider’s endpoints, for example, to access a proprietary model like Gemini or Claude which is not available as open source, or if the business case calls for “per-token” billing rather than a flat cost per GPU.
Architecture: ChatGPT-style Interface with Hosted Endpoints (AIaaS)
Download PDF: ChatGPT-style Interface with Hosted Endpoints (AIaaS)
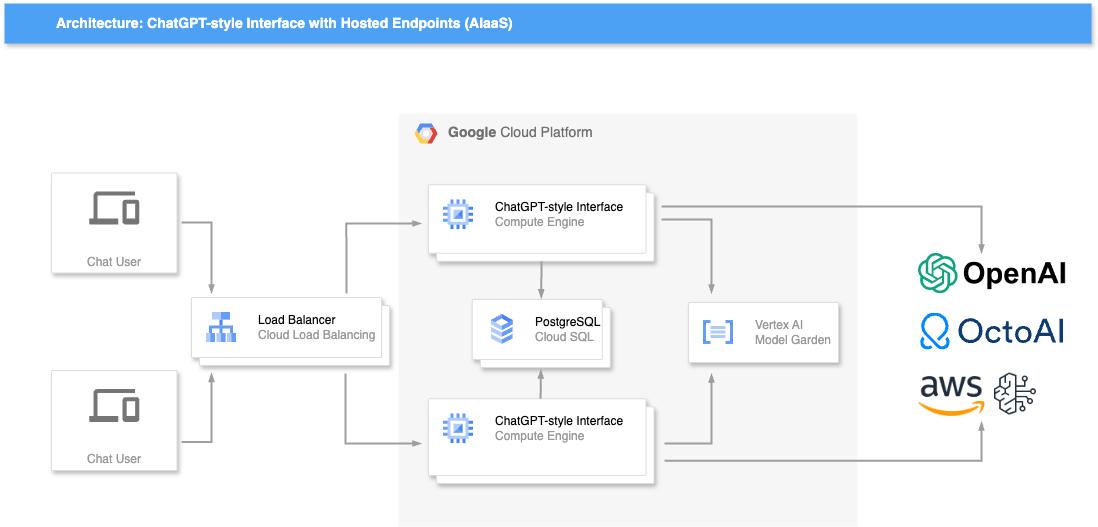
Any cloud provider can be substituted for Google Cloud, even though the architectural diagrams assume the usage of certain Google services such as Cloud Load Balancing and Cloud SQL. On AWS you can substitute Application Load Balancers and Amazon RDS, and with Azure, you can substitute Azure Load Balancers and Azure SQL.
For an on-premise deployment in your own private cloud, the managed load balancers can be substituted by HAProxy, and Postgres can be deployed with high availability using open source tools such as pgBouncer, or vendor solutions like Percona or Citus Data.
Regardless of your preferred deployment model (GPUs vs. hosted endpoints) and environment (on-prem or public cloud), the Autoize team of AI infrastructure architects can lead the adoption of AI LLMs with RAG while meeting your data protection & security requirements. Contact us for a demo and customized proposal (scope of work) for your AI RAG project.


