Cloudflare Workers is a serverless computing platform leveraging Cloudflare’s global network of datacenters, also known as edge locations, in over 300 cities and 100 countries around the world. The Workers service is used by Cloudflare’s customers to host & run serverless functions across the company’s expansive footprint, transforming the payload of an HTTP request before it’s served to an end user through the Cloudflare CDN. A Workers function could be something as simple as code that manipulates the HTML/CSS of a website, for instance to serve up dynamic content for A/B testing, or to process responses to a contact form on a static website. At the other end of complexity, a Worker can be an entire REST API for an application, eliminating the need to administer and manage an API gateway.
Cloudflare Workers AI is a more recent addition to the offering, providing access to managed AI endpoints with open source models, including the latest LLaMA 3 model. Any of the locations marked by an asterisk in Cloudflare’s list of datacenters are AI inference locations with GPUs deployed there, setting Workers AI apart with low latency compared to other models-as-a-service providers.
What’s more is that Workers AI has a generous free tier of 10,000 neurons/day — with no credit card required. “Neurons” are Cloudflare’s own measuring unit for compute usage on Workers. 10,000 neurons roughly translates to serving up 100-200 responses to an application prompting a large language model. It’s entirely possible that an individual developer, or even a small team might not exhaust the quota with their LLaMA usage. Besides LLMs, other types of AI models, such as BAAI for embedding and OpenAI Whisper for speech recognition are also supported by Workers AI.
Workers AI is working on an integration with Hugging Face Hub to make a broader list of community models available for use through the service.
Workers AI can be called with a POST request from a utility like cURL or Postman, or by using the Workers AI client library, which is an npm package for calling the service from your custom applications. Notably, Workers AI does not provide an OpenAI API compatible endpoint. Existing applications written with the OpenAI library should use an AI middleware layer like LiteLLM to translate the OpenAI calls into a format that Cloudflare can understand.
LibreChat and Nextcloud are two examples of open source applications that we consult on for our customers which support integration with AI through LiteLLM. LibreChat is a ChatGPT-style chat interface, allowing end users to privately have conversations with LLMs and chat with documents embedded in a vector database using RAG. NextCloud is a “file-sync-and-share” groupware application, enabling employees to roam across devices with their data and collaborate on documents together.
By spinning up a LiteLLM proxy container within your environment, or on Google Cloud Run, you can easily integrate any AI model on Cloudflare Workers AI with applications like NextCloud or LibreChat.
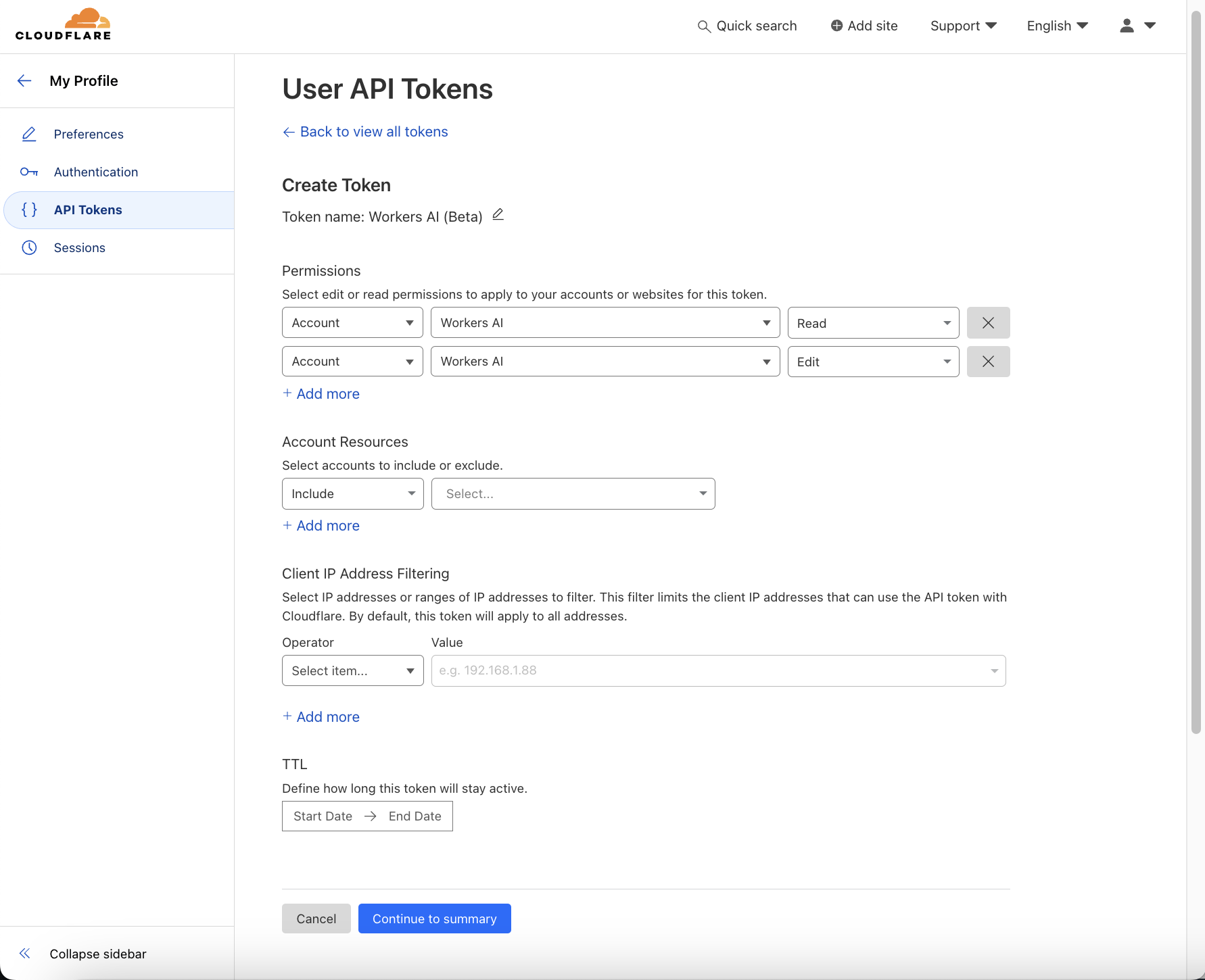
Generate a Cloudflare Workers AI API token.
Before you begin, you will need to generate an API token to your Cloudflare account with the permissions to read and edit the Workers AI service at https://dash.cloudflare.com/profile/api-tokens. In addition, you will also require your “Account ID” which can be found in the right column after signing into your account and choosing your Cloudflare zone.
Follow the wizard to create an API token for “Workers AI (Beta)” when prompted with the list of API token templates. If you know the public-facing IP addresses of the machine(s) where your LiteLLM service will run, then you can also restrict access by selecting “Is in” in the “Operator” dropdown under Client IP Address Filtering. If, instead, your LiteLLM proxy will be deployed to Cloud Run, then leave the API token valid for any IP address.
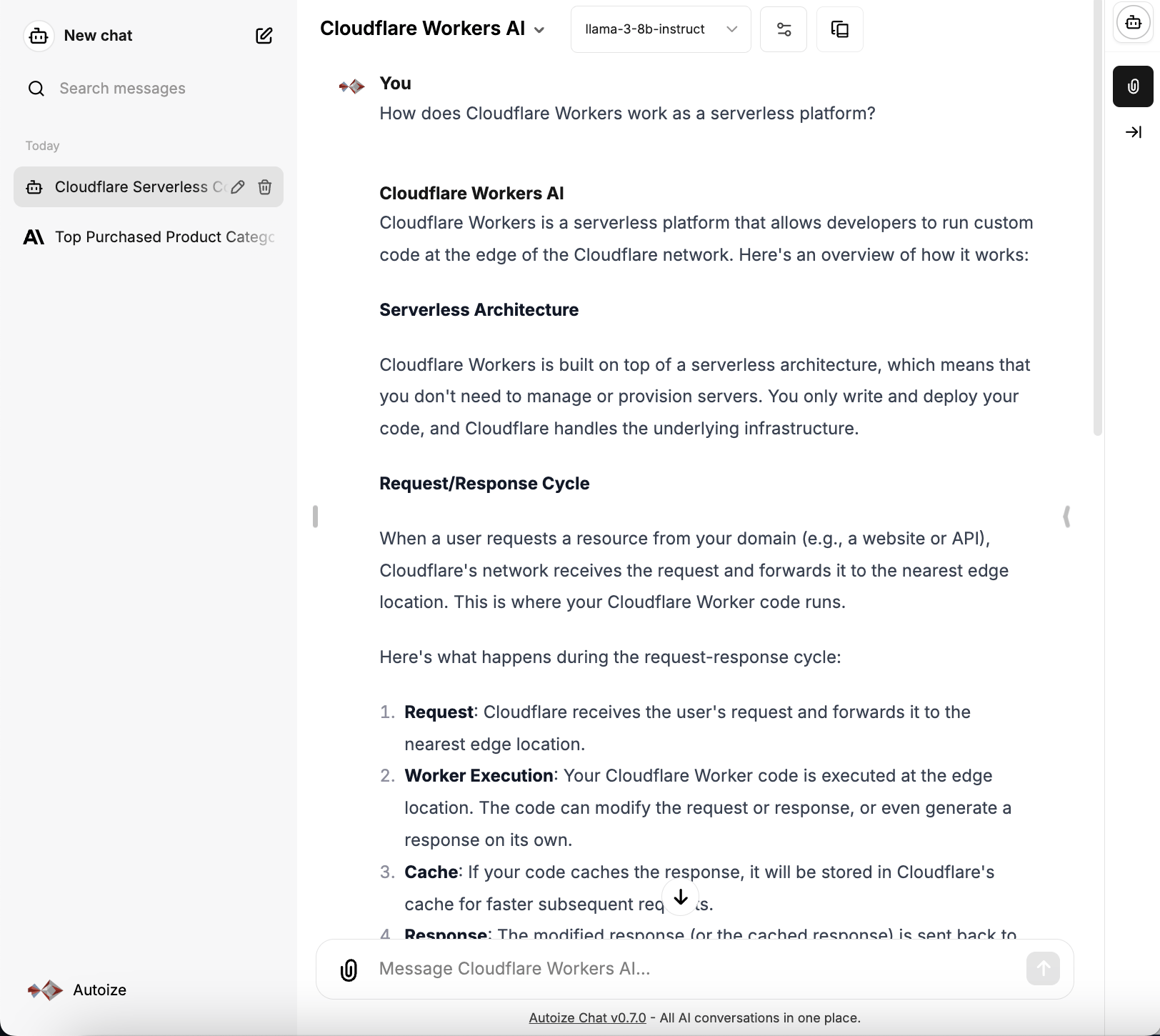
Example 1 – Define a LiteLLM proxy container and integrate Llama 3 with LibreChat.
We assume that on your machine exists a copy of the latest LibreChat GitHub repository. A “play by play” on how to deploy & configure LibreChat is outside of the scope of this article, but feel free to consult the docs or contact our AI architects for a consultation.
In the docker-compose.override.yml override file, add the following block under the “services” YAML key, where CLOUDFLARE_API_KEY is the API token generated earlier, and CLOUDFLARE_ACCOUNT_ID is the ID displayed in the account dashboard.
This service can be deployed in parallel with the default litellm container in the docker-compose.override.yaml.example, as it listens (and publishes to the host) on port 4000 instead of port 3000, and uses the service name litellm-workers-ai instead of litellm.
services: litellm-workers-ai: image: ghcr.io/berriai/litellm:main-latest environment: - CLOUDFLARE_API_KEY=foo - CLOUDFLARE_ACCOUNT_ID=foobar volumes: - ./litellm_workers_ai/config.yaml:/app/config.yaml ports: - "127.0.0.1:4000:4000" command: - /bin/sh - -c - | pip install async_generator litellm --config '/app/config.yaml' --debug --host 0.0.0.0 --port 4000 --num_workers 8 entrypoint: []
Create a subfolder in the project directory and a blank litellm configuration file.
$ mkdir ./litellm_workers_ai $ touch ./litellm_workers_ai/config.yaml
Open the newly created file litellm_workers_ai/config.yaml using the text editor of your choice and paste in the following contents to use the Llama 3 model, llama-3-8b-instruct.
model_list: - model_name: llama-3-8b-instruct litellm_params: model: cloudflare/@cf/meta/llama-3-8b-instruct litellm_settings: # module level litellm settings - https://github.com/BerriAI/litellm/blob/main/litellm/__init__.py drop_params: True set_verbose: True general_settings: master_key: sk-1234
To complete the integration, edit librechat.yaml in your project directory, and add the following block under the “endpoints” YAML key as a “custom” model provider.
endpoints: custom: - name: "Cloudflare Workers AI" apiKey: "sk-1234" baseURL: "http://litellm-workers-ai:4000" models: default: ["llama-3-8b-instruct"] fetch: false titleConvo: true titleModel: "llama-3-8b-instruct" summarize: false summaryModel: "llama-3-8b-instruct" forcePrompt: false modelDisplayLabel: "Cloudflare Workers AI"
Once done configuring the integration of LibreChat with the Llama 3 model on Cloudflare Workers AI, restart the Compose stack from the project directory of the Docker host. Select the “Cloudflare Workers AI” provider and the “llama-3-8b-instruct” model from the dropdown menus in the LibreChat interface to test and use the integration.
$ docker compose stop $ docker compose up -d
Example 2 – Deploy LiteLLM to Cloud Run and integrate Llama 3 with Nextcloud
For this example involving Nextcloud Hub with the OpenAI & LocalAI Integration and the Nextcloud Assistant apps, instead of using a LiteLLM container deployed on the same machine as the application, we will deploy LiteLLM to Cloud Run. Our earlier article has a more detailed explanation of the benefits of hosting an API proxy for AI using Cloud Run.
With a single gcloud run deploy command, containerized services on Cloud Run are automatically configured with a HTTPS service URL that depending on your ingress control setting may be accessed only internally within the Google Cloud project & VPC, or publicly over the Internet.
Because the Nextcloud instance we integrated with was located outside of Google Cloud, we opted to make the Cloud Run container accessible publicly without GCP authentication, but use the LiteLLM Virtual Keys feature to restrict access to the model. This also required us to supply a connection string to a Postgres database, in our case, hosted on the Azure Database for PostgreSQL – Flexible Server service.
If instead our Nextcloud instance was deployed on a Compute instance in the same Google Cloud project and VPC as our Cloud Run service, we could simply pass the –ingress=internal flag as part of the deploy command, and not necessarily need to use Virtual Keys or a Postgres DB. This is, of course, assuming that all of the services and compute instances in the VPC are trusted.
In the Google Cloud console, launch a Cloud Shell session at https://shell.cloud.google.com/?ephemeral=true&show=terminal. Be sure to replace the GCP project ID, Cloudflare API key, Cloudflare account ID, Postgres connection string, and the master key you wish to use for managing “virtual keys” in LiteLLM with the appropriate and secure values.
$ gcloud run deploy litellm-workers-ai\ --project=project-id-123456\ --platform=managed\ --args="--model=cloudflare/@cf/meta/llama-3-8b-instruct,--drop_params"\ --memory=2048M\ --port=4000\ --set-env-vars="CLOUDFLARE_API_KEY=foo,CLOUDFLARE_ACCOUNT_ID=foobar,DATABASE_URL=postgresql://<user>:<password>@<host>/<dbname>,LITELLM_MASTER_KEY=sk-456789"\ --image=gcr.io/project-id-123456/litellm:main-latest\ --allow-unauthenticated\ --region=us-central1
Once the service has finished deploying and is serving traffic, make a call to the /key/generate endpoint of the service URL to generate a “virtual key” beginning with the prefix “sk-” that Nextcloud will use to connect to the proxy.
$ curl 'https://litellm-workers-ai-ihyggibjkq-uc.a.run.app/key/generate' \ --header 'Authorization: Bearer sk-456789' \ --header 'Content-Type: application/json' \ --data-raw '{"models": ["cloudflare/@cf/meta/llama-3-8b-instruct"], "metadata": {"user": "foo@autoize.com"}}'
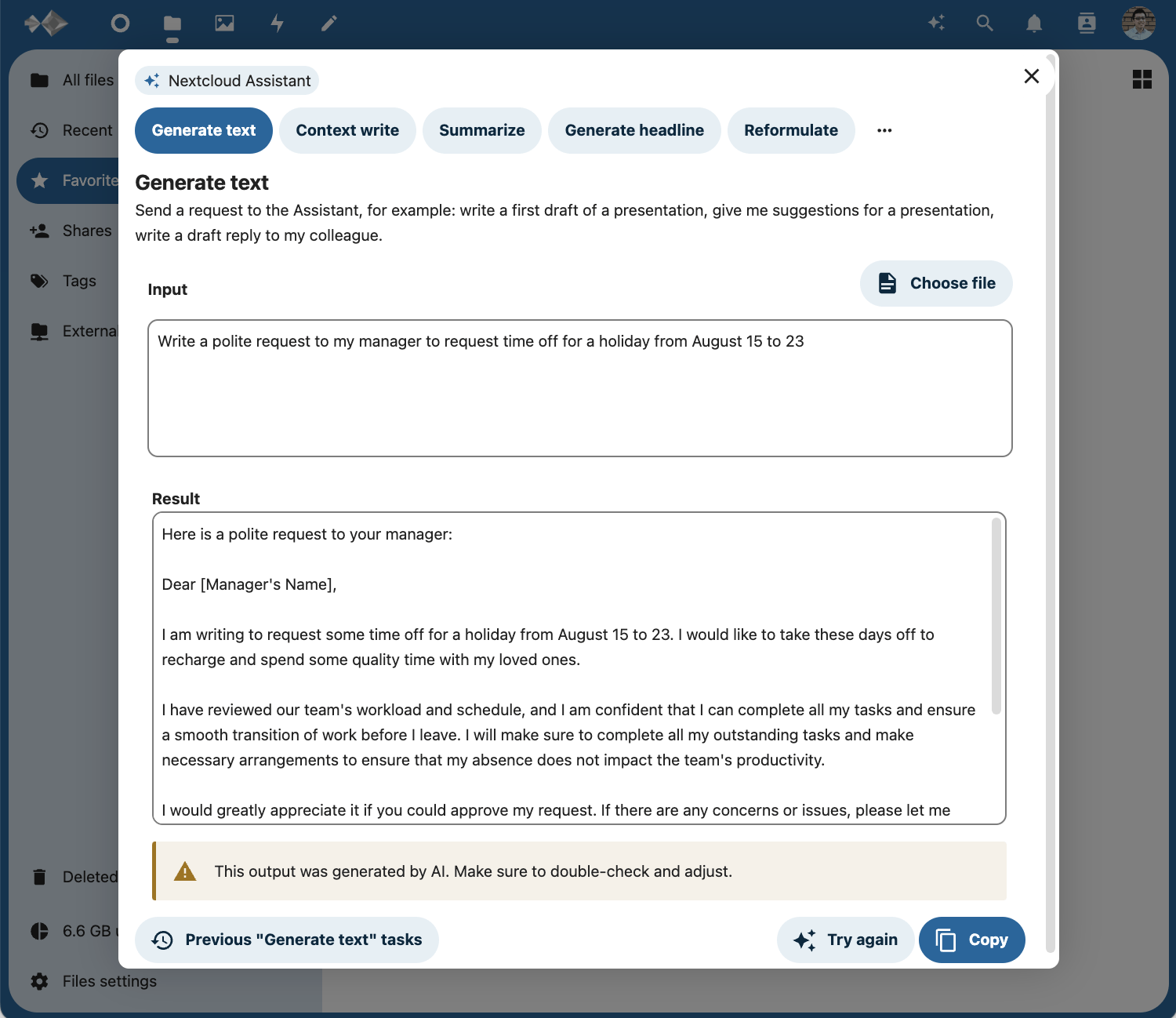
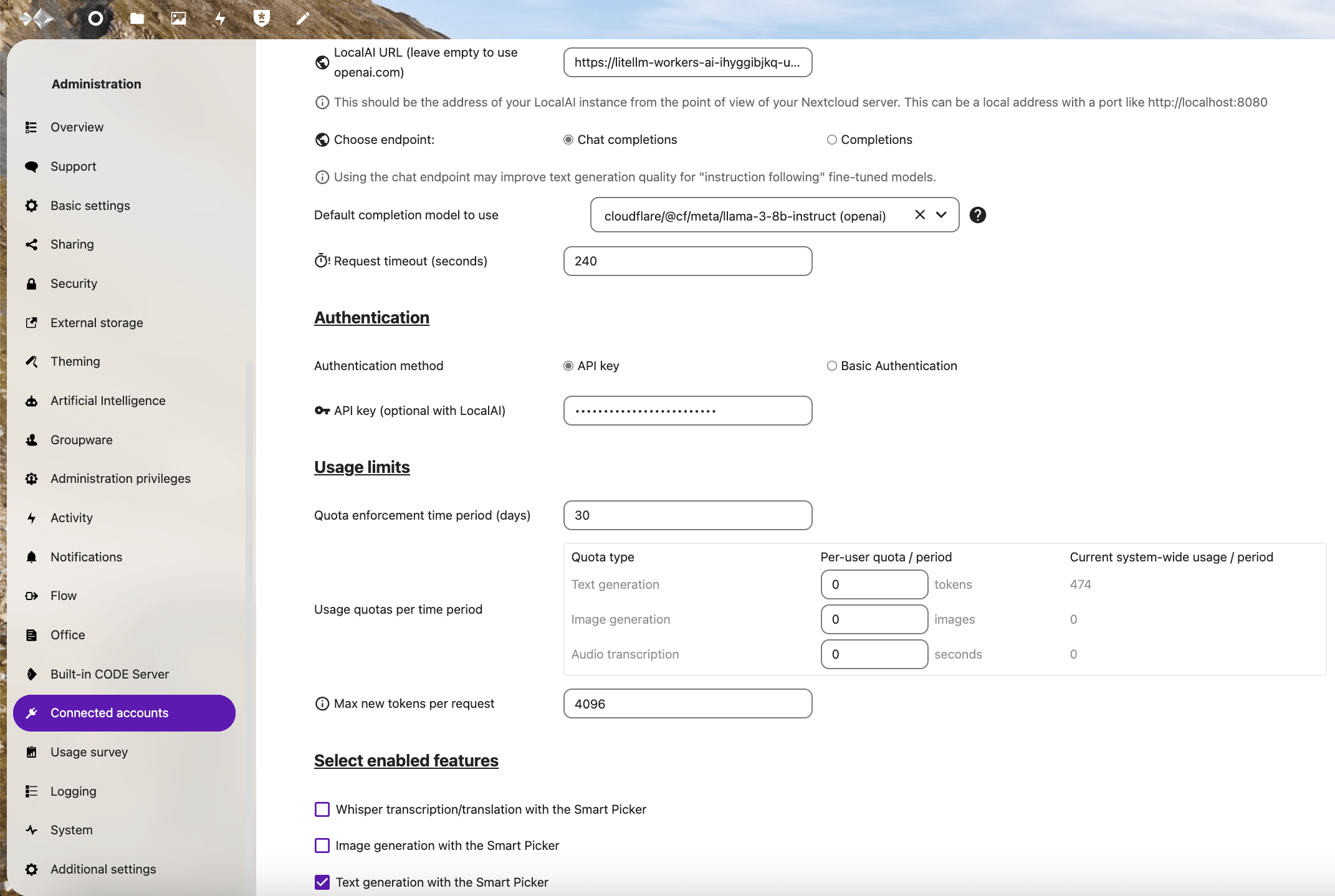
Then, log in to your Nextcloud instance as an admin user, then click on the profile image in the upper-right corner and select Administration settings. In the sidebar navigation to the left, scroll down and select Administration > Connected Accounts to configure the system-wide AI API key and endpoint URL for all users.
Here are the particular configuration settings to pay attention to:
- LocalAI URL: Unique LiteLLM service URL generated by Cloud Run (https://litellm-workers-ai-ihyggibjkq-uc.a.run.app)
- Choose endpoint: Chat completions (LiteLLM accepts calls at the /chat/completions endpoint)
- Default completion model to use: Prefilled with cloudflare/@cf/meta/llama-3-8b-instruct (openai) if the LiteLLM service is accessible by the Nextcloud instance
- API Key: LiteLLM virtual key beginning with “sk-” (Not the Cloudflare API token). If using the internal ingress option without virtual keys, “sk-1234”
- Max new tokens per request: Any value up to 8,000 if using the LLaMA 3 model
- Select enabled features: Text generation with the Smart Picker
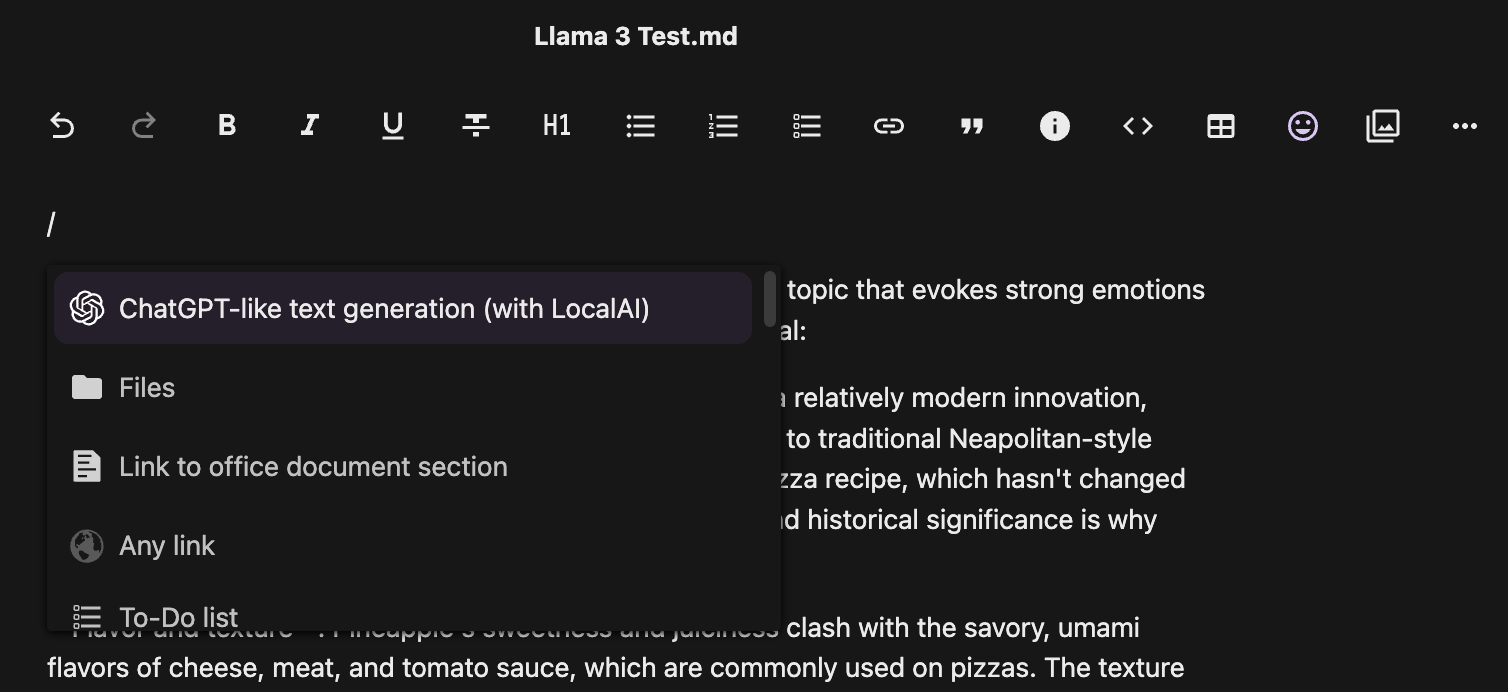
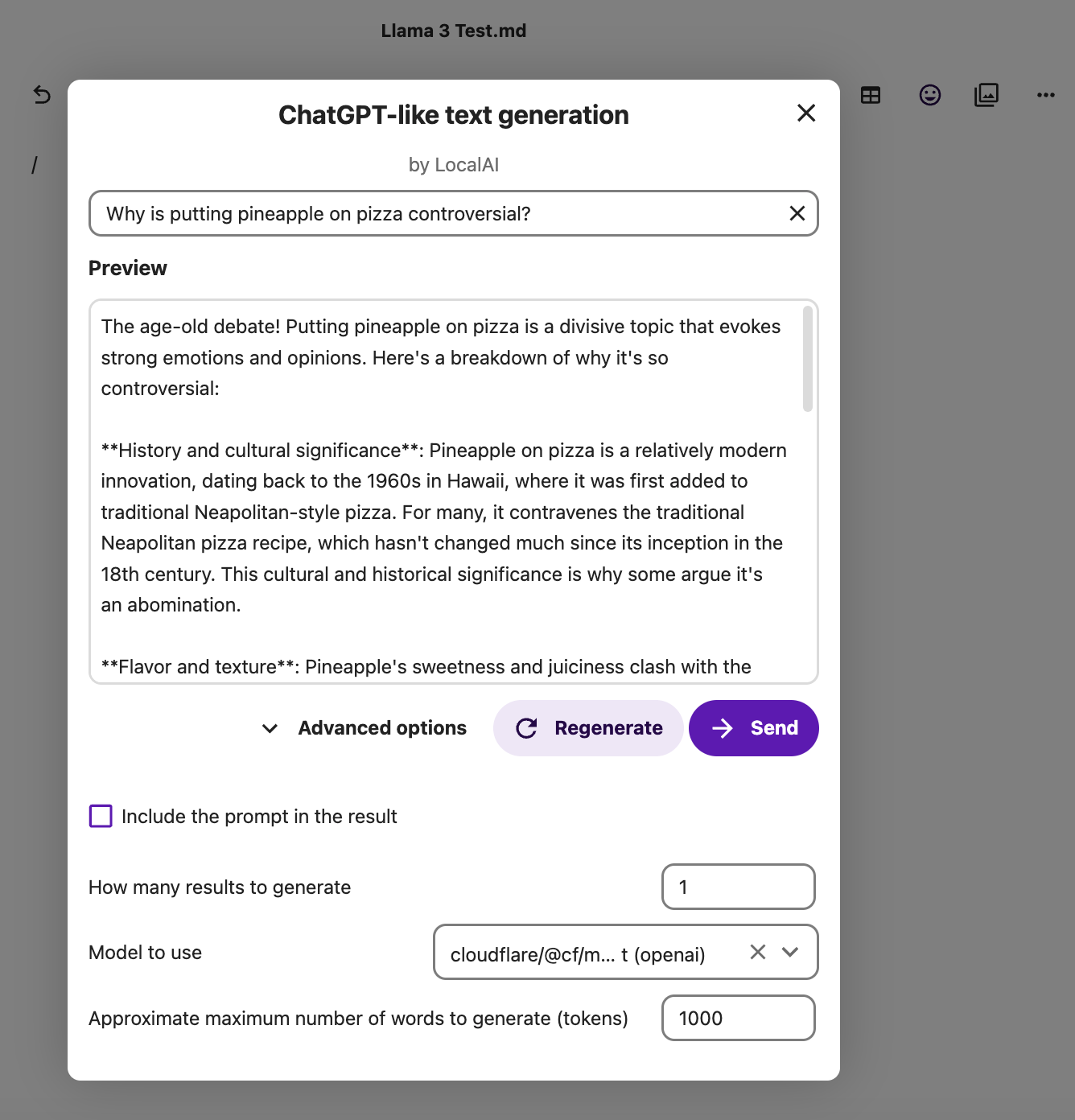
 If you configured everything correctly, you should be able to use the AI integration app in Nextcloud’s native apps, such as when editing a Nextcloud Text markdown file. Type a forward slash anywhere in the document and you should be presented with the option to use the ChatGPT-like text generation integration.
If you configured everything correctly, you should be able to use the AI integration app in Nextcloud’s native apps, such as when editing a Nextcloud Text markdown file. Type a forward slash anywhere in the document and you should be presented with the option to use the ChatGPT-like text generation integration.