AlloyDB is a fork of PostgreSQL on Google Cloud, optimized for high performance with vector embedding & retrieval workloads. As a PostgreSQL-compatible database, AlloyDB can be used as a drop-in replacement for any application that relies on a Postgres backend. It is deployed as a fully managed service on GCP, similar to Cloud SQL for PostgreSQL, but with additional clustering & caching capabilities engineered by Google.
In a production AlloyDB cluster with multiple read pool nodes, the read pool nodes can share the same Google Distributed File System as the primary node that accepts writes. The clustered file system eliminates the need for each node to have its own storage, and thus the need to keep the nodes synced up with one another. This increases the overall reliability of the system, in addition to reducing the storage cost — as each piece of data does not need to be stored multiple times across the cluster for analytical purposes.
Performance in AlloyDB is enhanced over standard PostgreSQL using Google’s ML techniques to inform the caching engine which tables, rows, and columns should be cached in-memory for up to 4X faster transactional workloads and 10X faster vector queries. Continuously during the operation of your application, AlloyDB learns what data in your database is queried the most frequently, and automatically caches it in RAM for rapid access
As we previously discussed about using Hugging Face Text Embeddings Inference to generate vector embeddings, embeddings models are used to convert text from documents into numerical representations that are stored in vector databases, which can then be used for retrieval augmented generation. RAG is an generative AI technique that uses a framework like LangChain to retrieve external data embedded in vector format to “ground” a model with additional context that will help it provide more informed answers.
The cost of AlloyDB in the us-central1 (Iowa) region (Apr 2024) for a minimal 1-node deployment with 2 vCPUs and 16 GB RAM — without a passive primary or any read pool nodes — is as follows. Each node you add will increase the cost by the according amount. Storage is charged according to the size of your datasets, and the retention period you choose for continuous and file-based backups.
- vCPU: $48.24/vCPU/mo x 2 vCPUs
- RAM: $8.18/GB/mo x 16 GB
- Total: $227.29/mo
Hugging Face also provides a hosted inference endpoint, including a free tier for certain large language and embeddings models for dev/test purposes. Using a Hugging Face API key, your application can authenticate to their shared endpoint, and call the supported models without the hourly cost of deploying a private endpoint. Upgrading to Hugging Face Pro gives you higher rate limits, ultra-fast inference endpoints, and access to a broader range of models on the HF serverless inference API. For a production workload, one would want to consider serving models using the Text Generation (TGI) and Text Embedding Inference (TEI) containers locally on GPU machines, or using Hugging Face Private Endpoints with GPU instances.
In this walkthrough, we will configure AlloyDB as a vector database for RAG with the ChatGPT-style interface LibreChat, using an embeddings model hosted by Hugging Face. The LibreChat GUI and RAG API will be deployed as part of a containerized stack on a Google Cloud compute instance.
Generate a Hugging Face API access token for the serverless inference API.
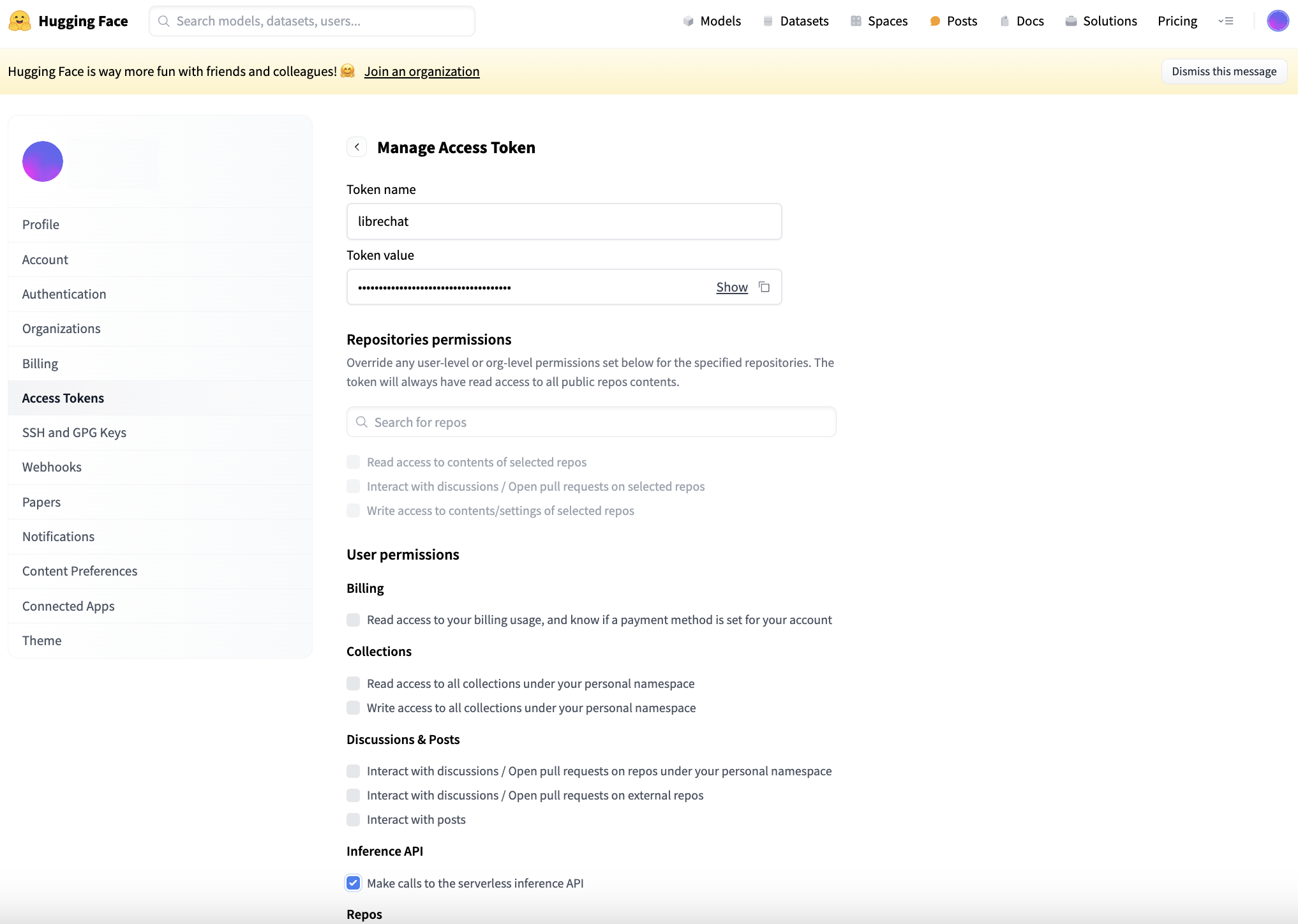 Create a new access token for Hugging Face of the “Fine-grained (custom)” type at https://huggingface.co/settings/tokens. Under User permissions, “Make calls to the serverless inference API” must be checked under the heading Inference API. The Token value is used to configure Hugging Face as an embeddings model provider for the RAG API service in the LibreChat stack.
Create a new access token for Hugging Face of the “Fine-grained (custom)” type at https://huggingface.co/settings/tokens. Under User permissions, “Make calls to the serverless inference API” must be checked under the heading Inference API. The Token value is used to configure Hugging Face as an embeddings model provider for the RAG API service in the LibreChat stack.
Enable the AlloyDB API in the Google Cloud console.
Provided this is your first time using AlloyDB in your Google Cloud project, search for “AlloyDB” in the search box at the top of the Google Cloud console, then click “Enable” to gain access to the service.
Then, click “Create Cluster” to launch the wizard to begin creating a new AlloyDB cluster.
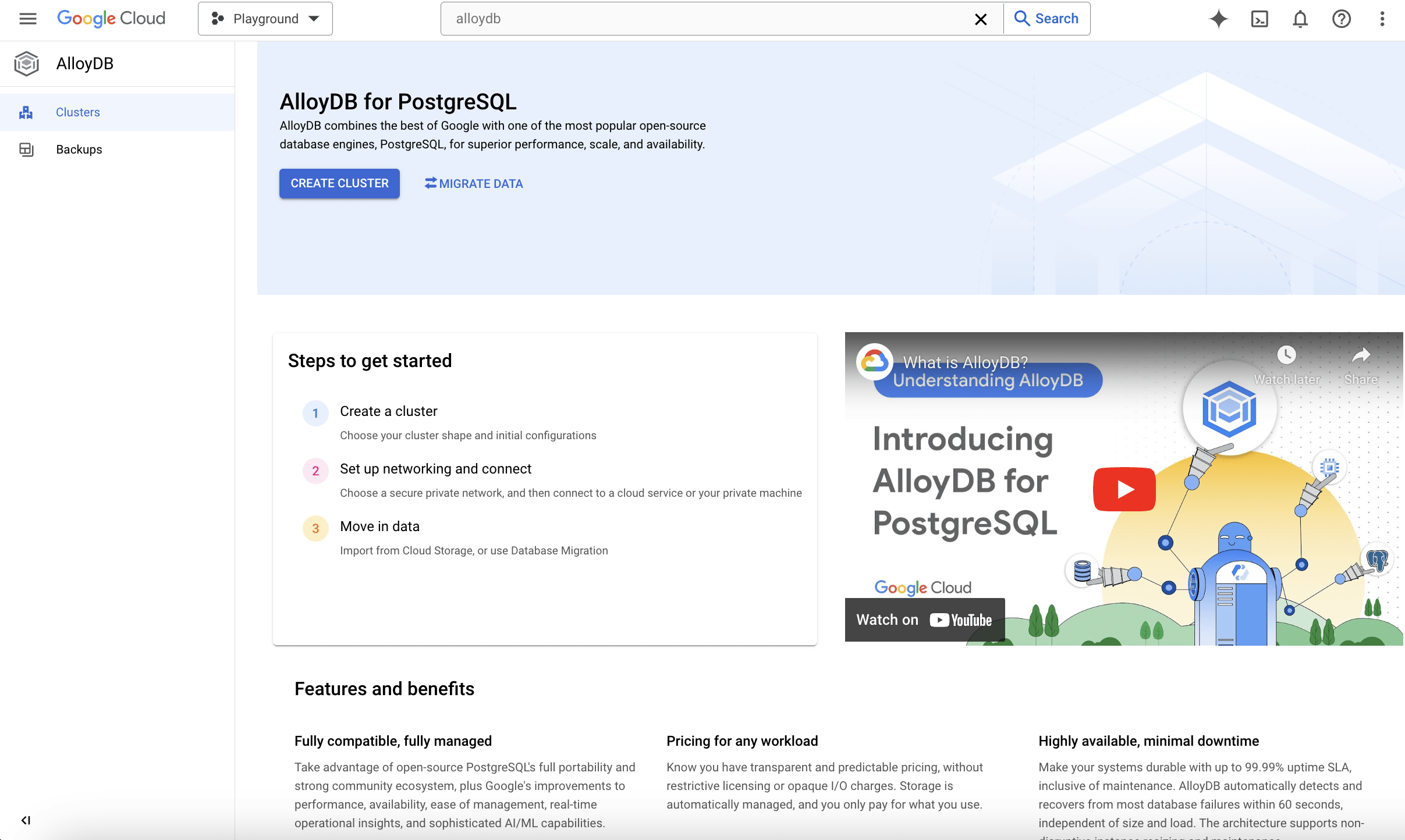
Create an AlloyDB cluster with the setup wizard.
There are a few steps to configure an AlloyDB cluster. Here are the options we went with for a minimal deployment. You can always scale up & down the cluster, and change the data protection policy according to your needs at a later time.
-
- Cluster configuration – Basic (Single-zone primary instance with no read pools. No failover.)
- For RAG in production, we might consider “Highly available” so there is an active primary, plus a passive secondary located in a different datacenter (zone).
- Cluster configuration – Basic (Single-zone primary instance with no read pools. No failover.)
- Cluster ID: rag-api
- Password: Automatically generated
-
-
- This will be the password to the initial “postgres” user.
-
- Database version: PostgreSQL 15 compatible
- Region: us-central1
- Network: default
-
-
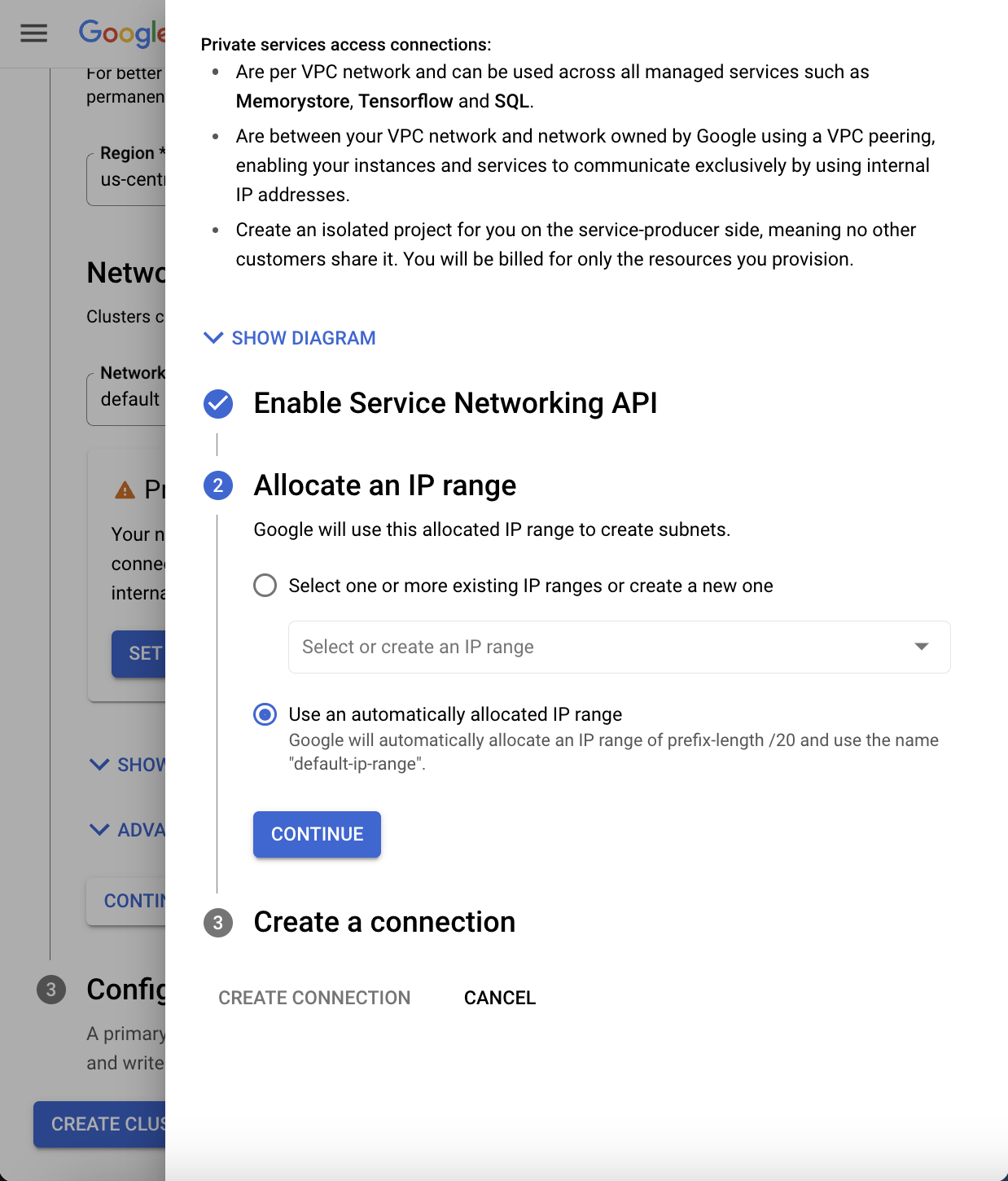
- Enable the Service Networking API for private services access.
- The AlloyDB cluster is actually deployed in a separate internal project and VPC from your application servers. VPC peering allows data to traverse the Google network between these VPCs.
- Use an automatically allocated IP range.
- Enable the Service Networking API for private services access.
-
- Data protection:
- Google-managed continuous data protection – Yes
- Default is 14 days
-
-
-
- This determines how many days you can roll back transactions using the WAL logs, and is separate from file-based backups.
-
-
- Machine: 2 vCPU, 16 GB
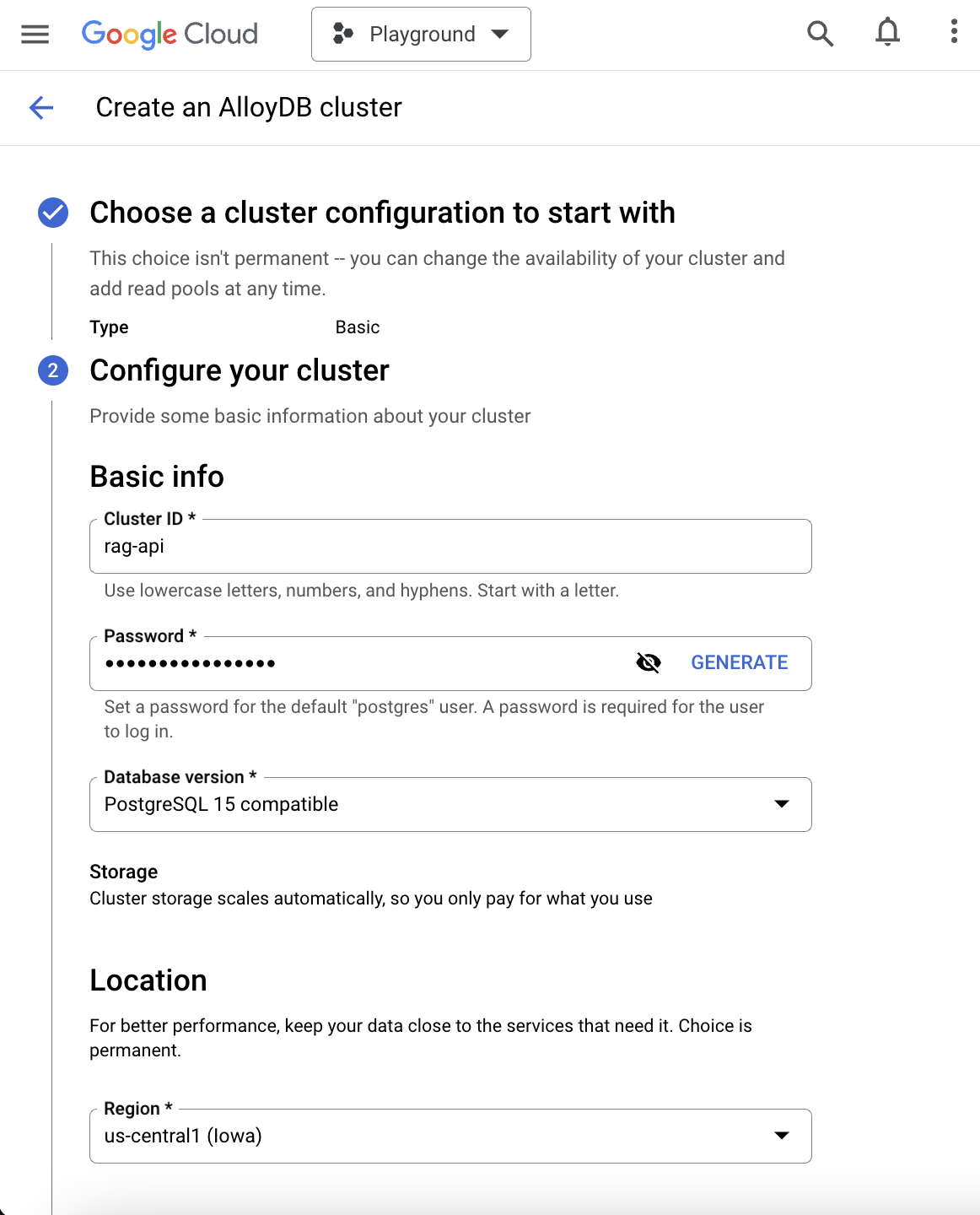
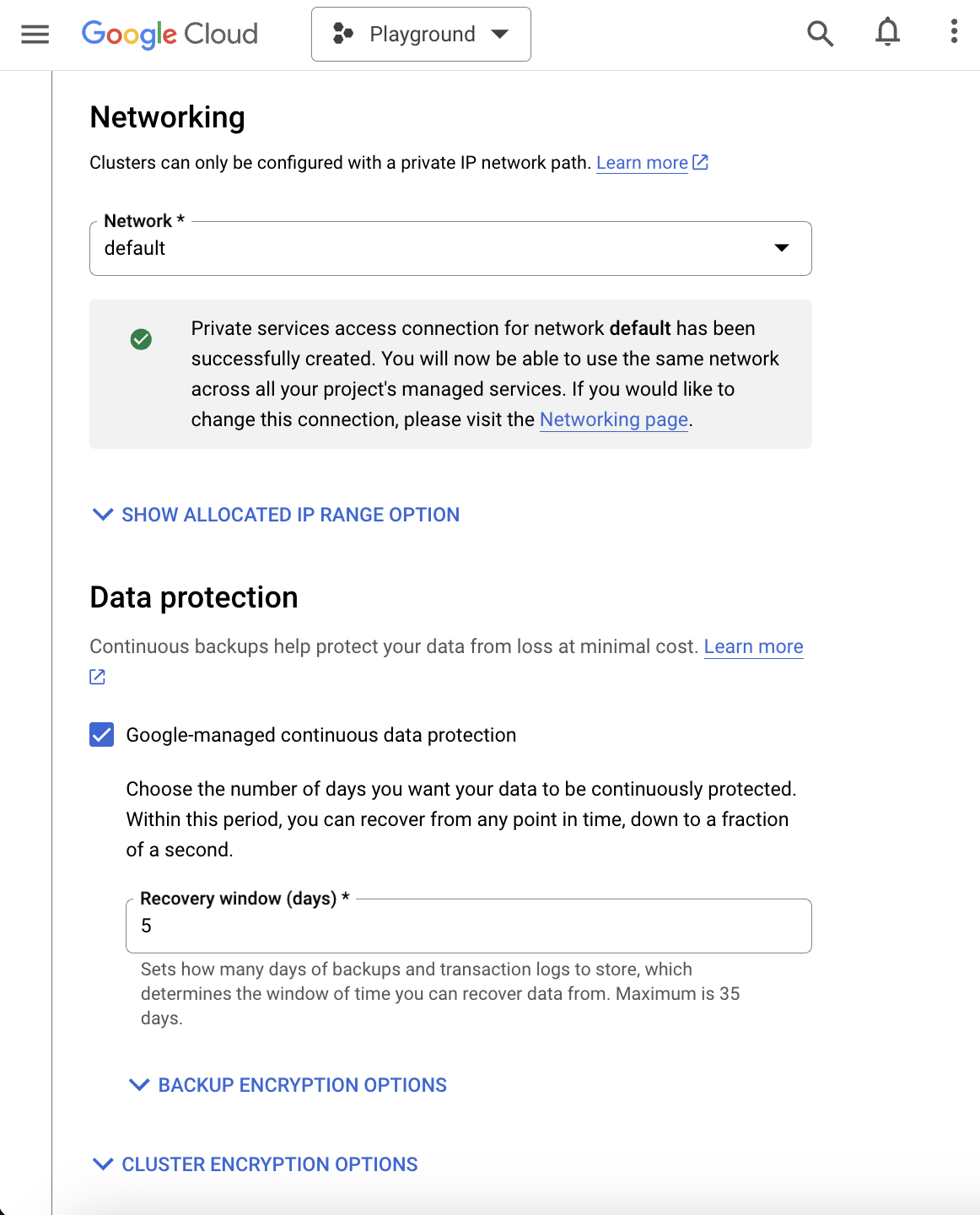

Allow unencrypted connections from your Google Cloud project’s VPC.
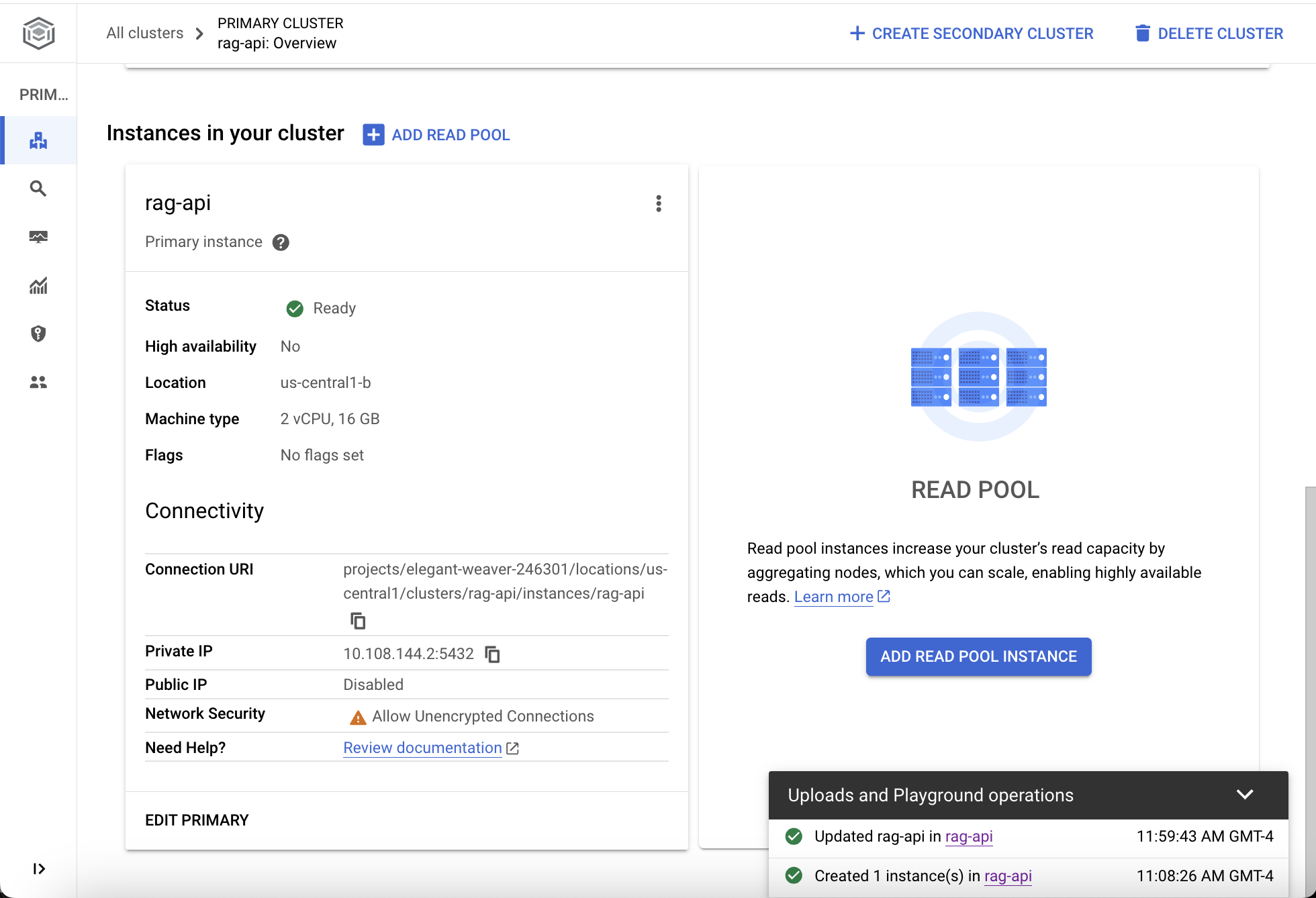
Once your AlloyDB cluster has been successfully deployed and is in the “Ready” status, check the Connectivity section for the private IP address to connect to the AlloyDB instance from any Google Cloud VPC peered to the AlloyDB VPC for private services access. If your application like LibreChat relies on a plaintext connection to PostgreSQL, click “Edit Primary” and uncheck “Only allow SSL connections” under Advanced configuration options.
Because the LibreChat application communicates with AlloyDB only on Google Cloud’s private network, your data remains protected from prying eyes on the Internet. This assumes that your LibreChat containers are hosted on a Google Cloud compute instance within the peered VPC.
Configure RAG with Hugging Face Embeddings Models & AlloyDB Vector Database
The embedding model that we will use is hosted by Hugging Face external to the LibreChat stack, so the default librechat-rag-api-dev-lite image in docker-compose.yml file for the rag_api service is sufficient (the librechat-rag-api-dev image is for local embeddings).
In the project directory of the LibreChat stack, specify the following environment variables in the .env file, where “HF_TOKEN” is the access token previously generated from the Hugging Face dashboard.
EMBEDDINGS_PROVIDER=huggingface EMBEDDINGS_MODEL="sentence-transformers/all-MiniLM-L6-v2" HF_TOKEN='hf_AbCd'
Then in the “environment” YAML key of the rag_api service in the docker-compose.override.yaml file, set the following credentials as environment variables, where “DB_HOST” is the private IP given for the primary AlloyDB node and “POSTGRES_PASSWORD” is the password for the postgres user specified in the AlloyDB setup wizard.
services: rag_api: image: ghcr.io/danny-avila/librechat-rag-api-dev-lite:latest environment: - DB_HOST=10.xxx.xxx.x - DB_PORT=5432 - POSTGRES_DB=postgres - POSTGRES_USER=postgres - POSTGRES_PASSWORD='pgpass'
After saving the changes to the config files, restart the LibreChat container stack from the terminal of the Docker host machine with the docker compose down and docker compose up -d commands to recreate the containers with the newly set environment variables.
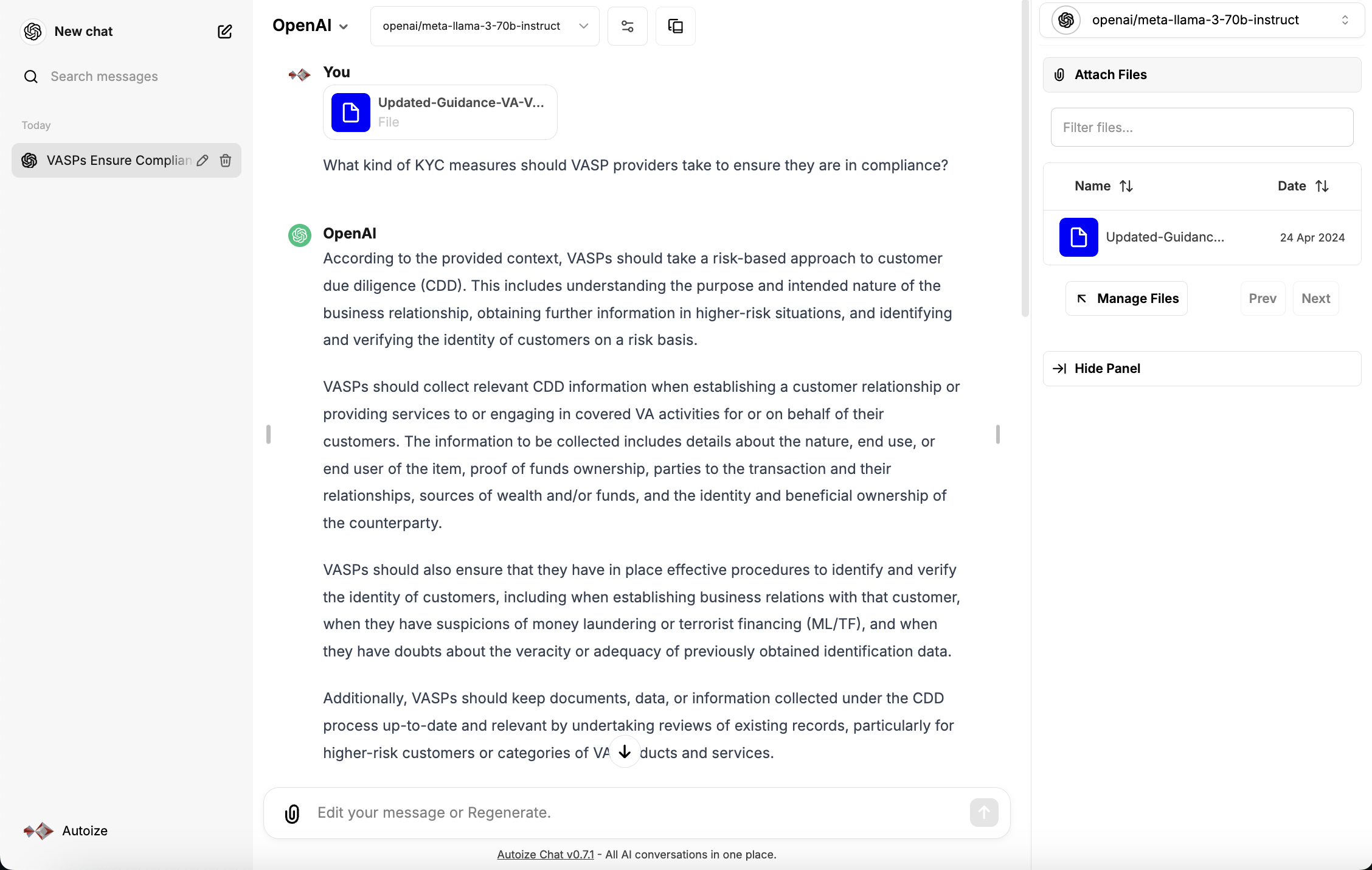
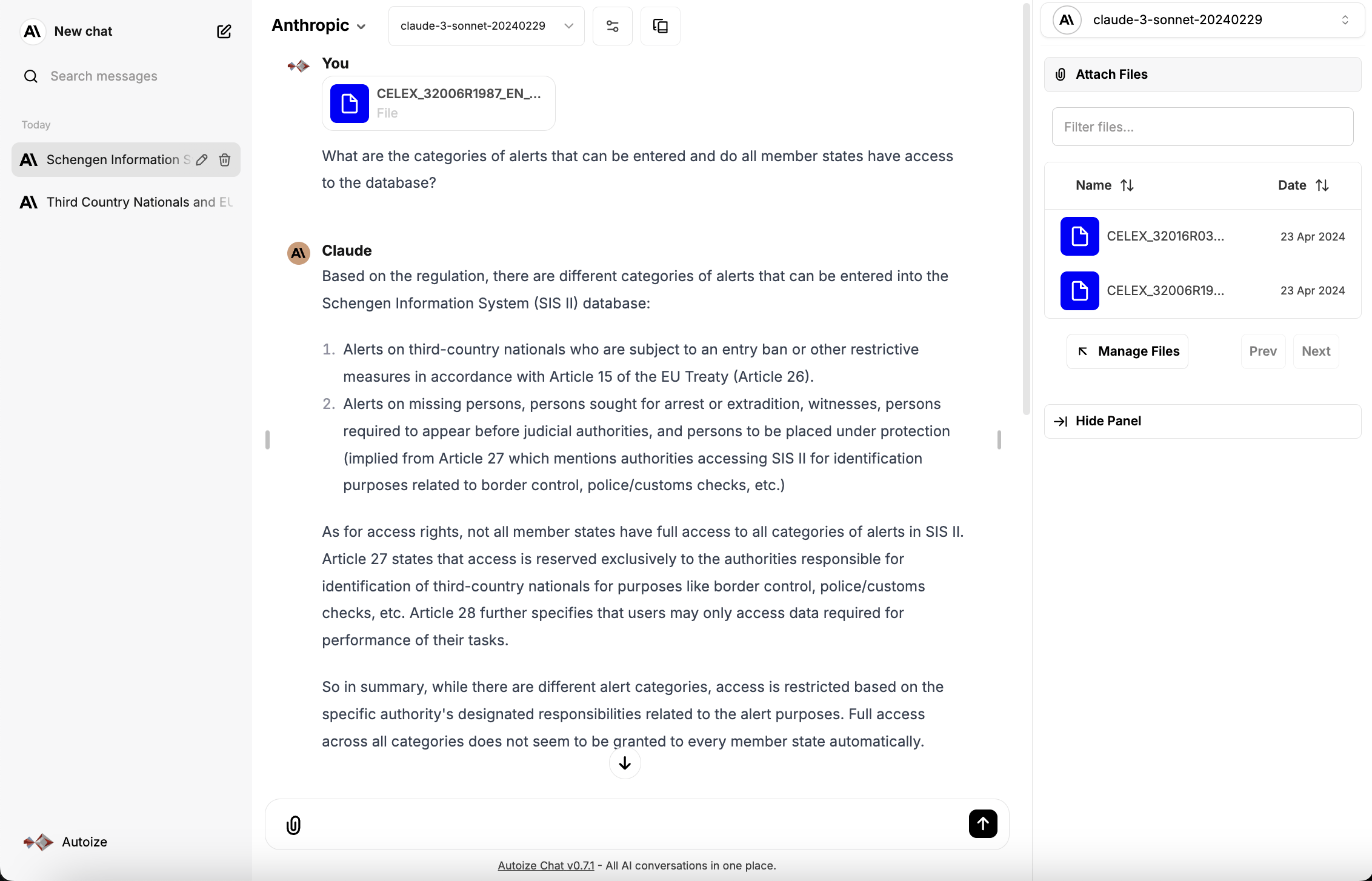
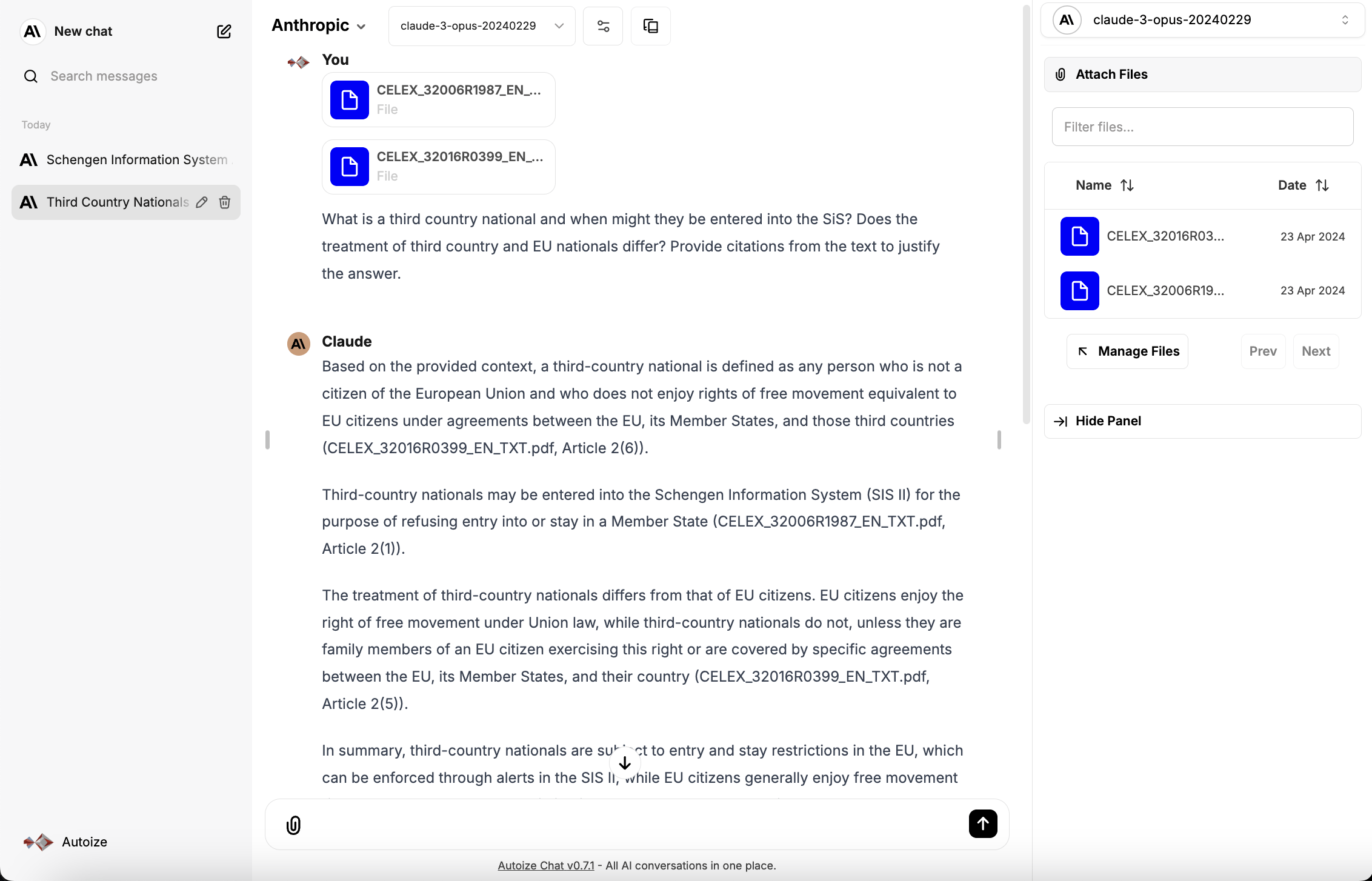
When chatting with a large language model in the LibreChat interface, users can attach document(s) for the LLM to use as context when responding to their prompt. When a document is uploaded, it is handed off to the embeddings model to generate vector embeddings, which are then stored within the langchain_pg_embedding table of the AlloyDB database.
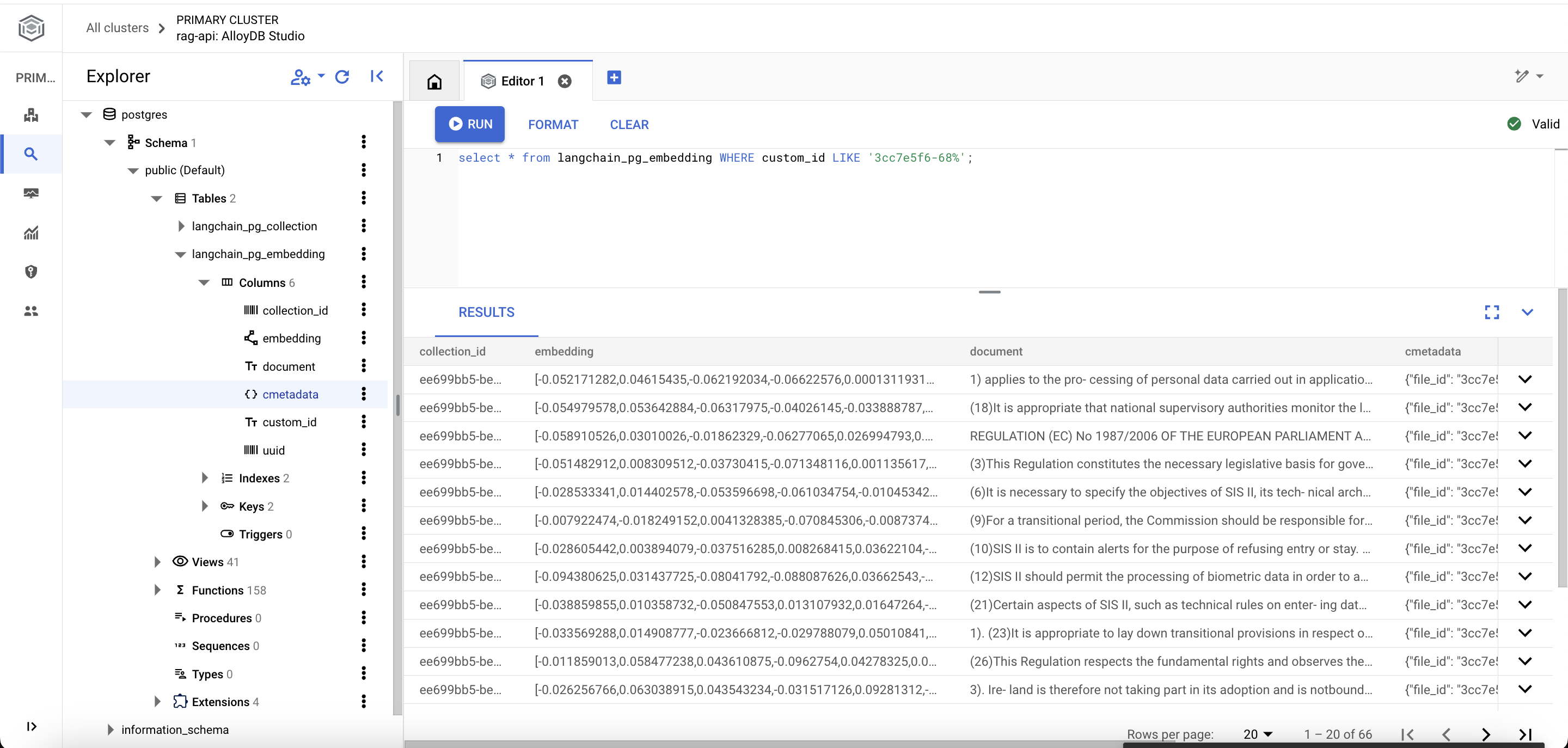
During the conversation, LibreChat leverages the LangChain framework to retrieve the vector data from AlloyDB, perform semantic search to predict the parts of the document that are the most relevant to the user’s prompt, then call the large language model with the user’s prompt in conjunction with the document excerpt.
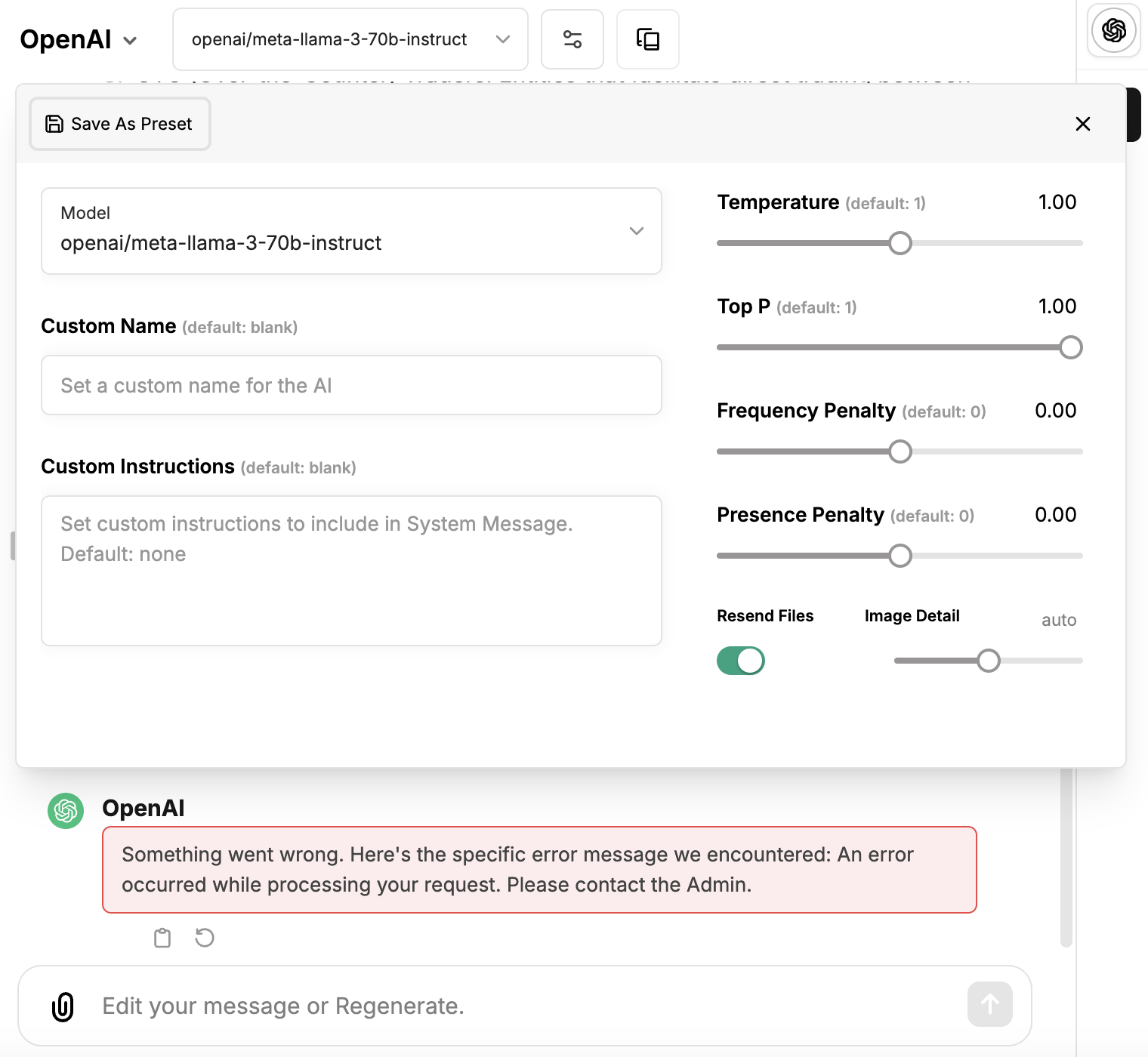
If you encounter an error like “Something went wrong. Here’s the specific error message we encountered: An error occurred while processing your request. Please contact the Admin.” when chatting with the model, click the “Settings” icon beside the model dropdown. Then, toggle the slider “Resend Files” to off. To avoid the error with future multi-turn conversations, save this setting as a preset, and set it as the default preset from the “Presets” dialog.