

The addition of the RAG API microservice to LibreChat in version 0.7.0, the most rapidly trending open source ChatGPT clone, swings the door open to chatting with PDFs and documents using any supported AI model, in a private, self-hosted environment. Grounding an AI model with data sources embedded into a vector database using a technique known as Retrieval Augmented Generation (RAG) is useful for a few reasons. RAG augments an AI model with knowledge beyond its “knowledge cut-off” and assists a chatbot in generating better responses with more context about the specific situation the user is asking a question about. It is a cost-effective and efficient way to increase the usefulness of a foundation model, without needing to train or fine-tune it using considerable time on expensive GPUs.
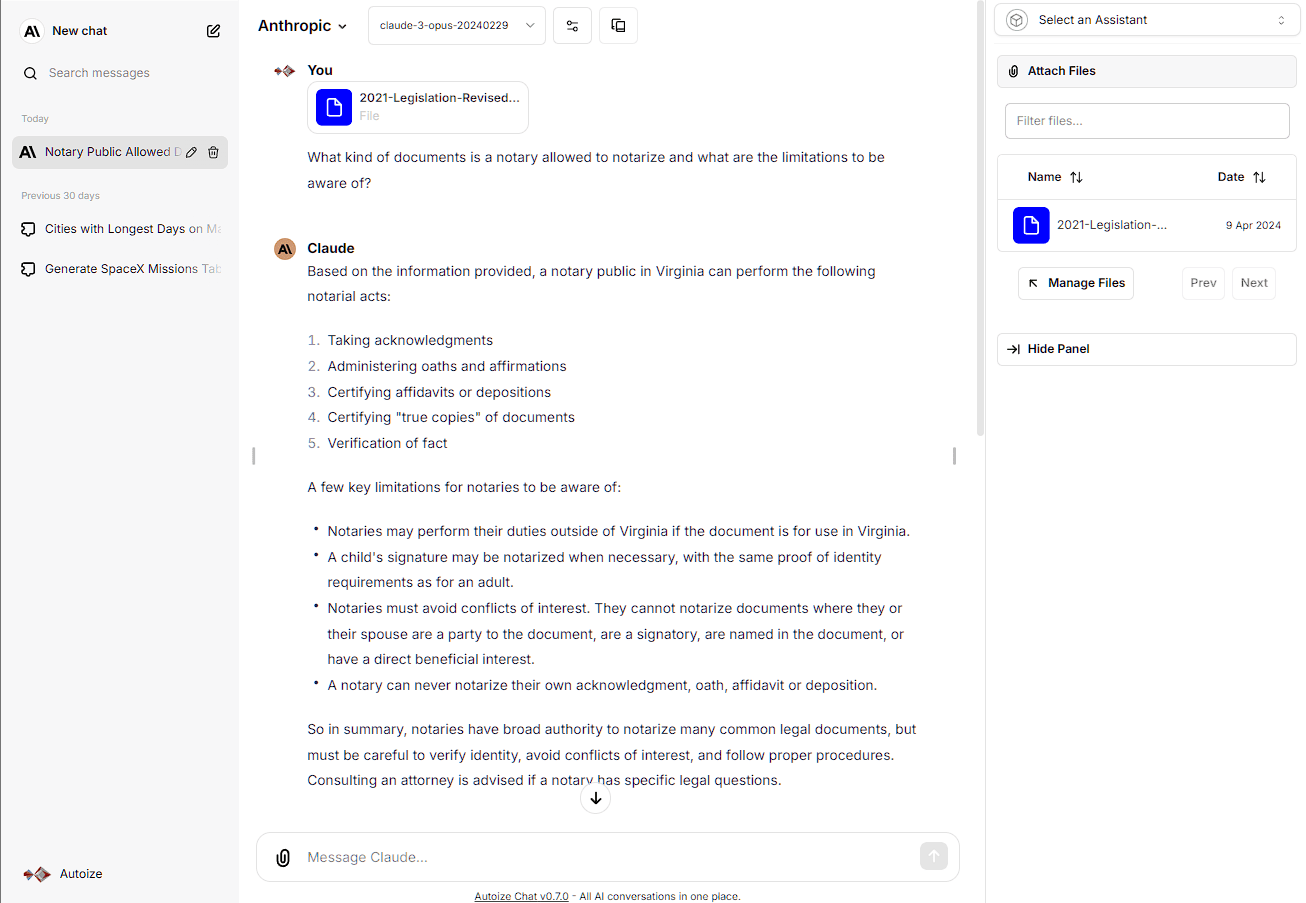
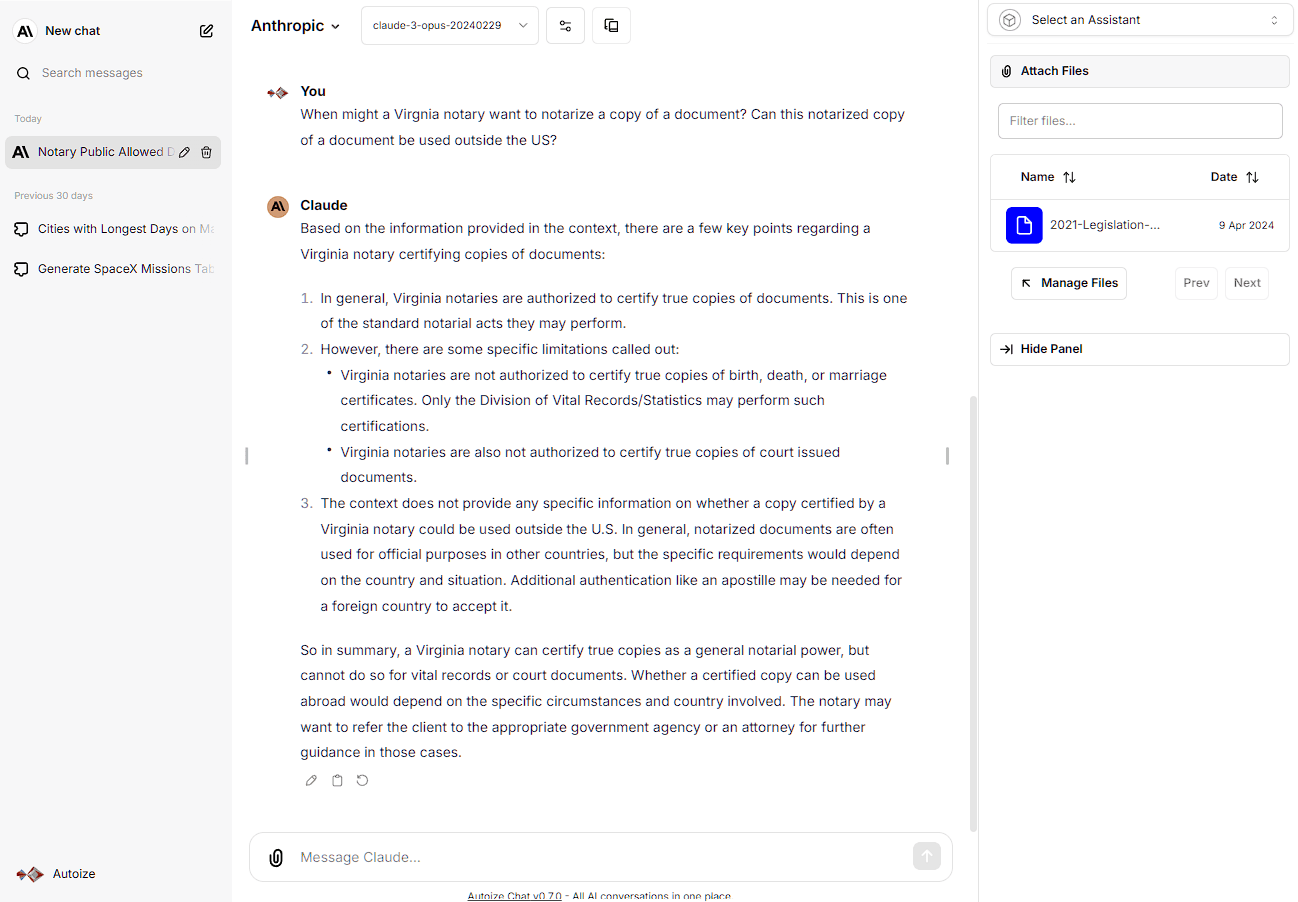
The RAG API microservice in the LibreChat stack is a REST API service that listens for calls from the main LibreChat app, known as the API. When a user uploads a PDF file (or other supported file type) through the LibreChat frontend, the API hands off the file to the RAG API, which calls the configured embeddings API to convert said file into a numerical representation called a “vector embedding” and write it to a Postgres database. Currently, the supported embeddings APIs are: OpenAI, Azure OpenAI, HuggingFace, HuggingFace TEI, and Ollama.
For organizations who require keeping their document data strictly private on their own network, using TEI (Text Embeddings Inference) and Ollama will be the way to go as the TEI and Ollama containers can be self-hosted inside your virtual private cloud or completely on-premise. The BAAI and Nomic AI embedding models are the most commonly supported models for TEI and Ollama, respectively. While it is recommended for performance to use a GPU-accelerated machine to run TEI or Ollama in production, you can still embed data to a vector database using the BAAI or Nomic AI models using CPUs only.
Azure OpenAI and Hugging Face are both hosted APIs, but provide the option of hosting a private endpoint that is for your organization’s exclusive use. In the case of Azure OpenAI, this can eliminate the necessity of your users’ prompts or datasets to traverse the Internet, as a model deployed on the Azure OpenAI service can be assigned a private IP in the same VNET subnet as your other Azure resources. For OpenAI’s default models, you only incur costs per-token when you call the model through the API, but fine-tuned models have an hourly cost whether you are using them or not. With Hugging Face’s Inference Endpoints, your endpoints are hosted on dedicated compute instances with GPUs that can “scale to zero” when they are not in use, reducing your overall costs.
Out of the embedding APIs supported by LibreChat’s RAG API, OpenAI (not to be confused with Azure OpenAI), provides the weakest privacy guarantees, compared to the other options. OpenAI is the developer platform associated with OpenAI Global LLC itself, providing no separation from the same company harvesting data to train the GPT models. Through Azure OpenAI, you can get access to the same models, but with Microsoft’s contractual guarantee that they will not use your users’ conversations and proprietary data for model training. For this reason, we recommend using RAG API with OpenAI for development & testing purposes only.
Other than data privacy, one of the most significant advantages of deploying RAG using the LibreChat stack is the ability to apply the most advanced AI models, such as those from Anthropic, with a “large context window” to your custom data. A large context window means that the model can consider embedding data and previous chat “turns” as lengthy as hundreds of pages of text, without exceeding the maximum context length or excessively truncating the context. Supporting a large context can make an AI model seem much “smarter” and more useful, as users will need to repeat the context from earlier parts of the conversation far less often.
For instance, Anthropic’s Claude 3 Opus model supports a context length of 200K tokens, which is equivalent to 150K words or 500 pages of text. Also, Claude 3 Opus’ inference performance exceeds that of OpenAI’s GPT-4 at a fraction of the cost. Claude 3 Opus (200K) is priced at $15 per million input tokens and $75 per million output tokens, while Azure OpenAI GPT-4 32K is priced at $60 per million input tokens and $120 per million output tokens. Opus is ¼ of the cost for input tokens and ⅔ of the cost for output tokens. For an AI application that is scaling to thousands of users or more, the difference in cost can be phenomenal.
If you are already using LibreChat, you will need to upgrade your LibreChat stack to the latest version to take advantage of the new RAG API feature. Provided that you have been making customizations to the stack using the docker-compose.override.yml file instead of editing the docker-compose.yml file directly, you can simply upgrade the stack by running the following commands in your project directory. Any environment variables set in your .env file, as well as any host data folders (e.g. if you are running MongoDB locally or have a LiteLLM config folder) will be preserved.
$ docker compose down $ git pull $ docker compose pull $ docker compose up -d
If however, you modified the docker-compose.yml file directly, you should backup that file to a separate directory, run a git reset, then apply those changes through the docker-compose.override.yml file instead. The LibreChat provides an example for the override file, docker-compose.override.yml.example, which you can begin working with as a template.
Provided that you already have some LLM endpoints such as an OpenAI-compatible API (such as LiteLLM) or Anthropic configured for LibreChat, all you really need to do to begin using the new RAG API is configure the following environment variables in your .env file that is in the project directory. The full list of supported variables can be found at the RAG API Github repository.
In the example below, you would need to replace RAG_AZURE_OPENAI_API_KEY with your actual API key, and resource-name in RAG_AZURE_OPENAI_ENDPOINT with the name of the Azure resource containing your OpenAI model deployments. DEBUG_RAG_API can be optionally set to true if you require the traces of the API calls (and callbacks) in the Docker logs, but for production it should be set to false.
RAG_AZURE_OPENAI_API_KEY=foo123 RAG_AZURE_OPENAI_ENDPOINT=https://resource-name.openai.azure.com DEBUG_RAG_API=false EMBEDDINGS_PROVIDER=azure EMBEDDINGS_MODEL=text-embedding-3-small
In the Azure management portal, through the Azure OpenAI Service blade, select Model deployments under Resource Management. Then, click the “Manage Deployments” button to go to the Azure OpenAI Studio. From there, you can deploy an embedding model corresponding to the name of the EMBEDDINGS_MODEL that you specified in the environment variable.
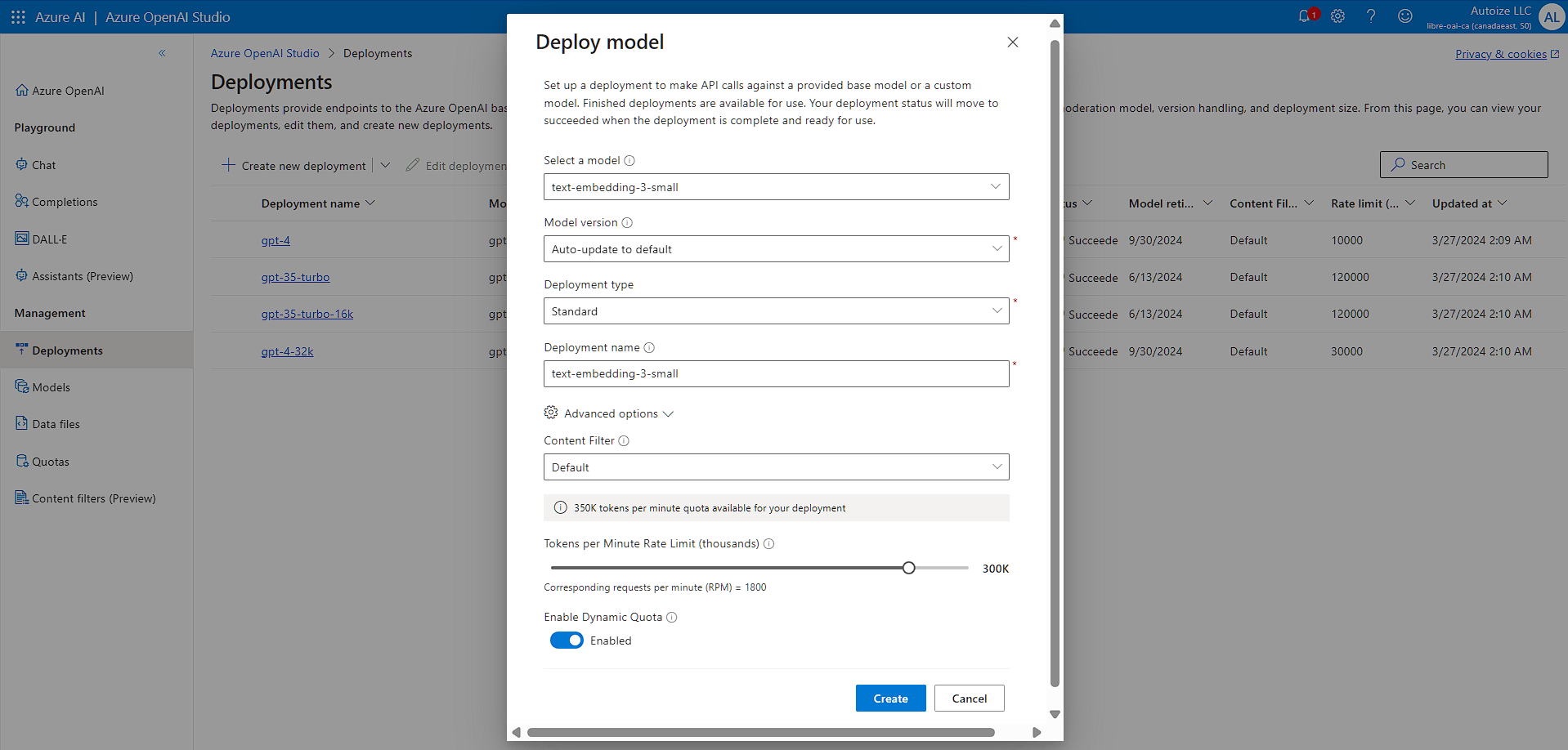 It is a good idea to set the Tokens per Minute Rate Limit to at least 300K to avoid errors such as
It is a good idea to set the Tokens per Minute Rate Limit to at least 300K to avoid errors such as
{'error': {'message': 'Request too large for text-embedding-3-small in organization org-foo on tokens per min (TPM): Limit 150000, Requested 286212. The input or output tokens must be reduced in order to run successfully.
Be sure to do a docker compose down and docker compose up -d after making any changes to the environment variables in your project. For a minimal set up, this should work to get started with RAG using LibreChat, but for production use, we recommend disabling the vectordb service in the Compose stack and specifying the credentials for an external, managed Postgres database with pgVector support instead, such as Azure Database for PostgreSQL or Google AlloyDB.
Also, as mentioned previously, it can be wise to set up an embedding service such as Hugging Face TEI or Ollama locally if you want to generate the vector embeddings without sending your document data to an external API such as the Azure OpenAI embedding model. You will need to consider what type of GPU instances you need and how to load balance the traffic to them, such as by using an AI API Proxy such as LiteLLM or a cloud load balancer.
Contact our AI infrastructure specialists for expert, hands-on help with planning how to implement your RAG strategy in a secure & compliant manner, while accelerating the time to benefit of generative AI for your team.


