GPUs increase the speed of LLM inference and embedding by an average of an order of magnitude or more, enabling a model to generate tokens as quickly as a user can read. As a typical reading speed is two to three words per second, and a token is 4 characters in the English language, a 7-10 tokens per second (tps) is a sufficient token generation speed for natural-feeling conversations with a chatbot.
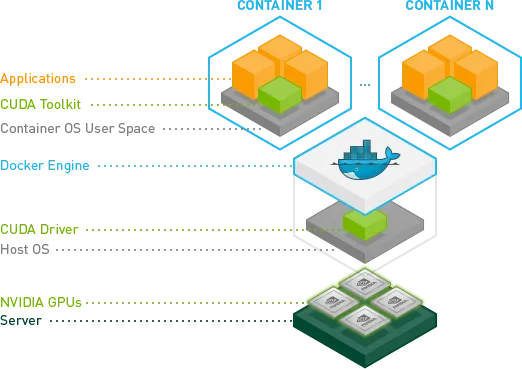
There are a few more steps you must take to enable GPU acceleration for your Ollama or TGI containers after you have provisioned some GPU enabled VMs with your IaaS cloud provider. GPU is a “capability” which must be enabled in Docker by installing the NVIDIA drivers for the machine’s operating system, as well as the NVIDIA container toolkit. For this discussion, we will use Google Cloud Compute Engine.
As NVIDIA cannot currently ship GPUs as quickly as the demand is growing for them, it is quite a finite resource on many public clouds. New cloud accounts with the Big 3 (AWS, Google Cloud, Azure) may start with a relatively low quota for the number of GPUs they may provision, which will increase as the account attains a longer billing history. Smaller providers such as Paperspace (recently acquired by DigitalOcean) or the OctoAI Compute Engine may have more availability of GPUs. For dev/test purposes, trying a “spot” instance type which can be “pre-empted” at any time by the cloud provider, and is automatically stopped every 24 hours, may also help with GPU shortage.
On Google Cloud, the least expensive GPU instance types will typically be VMs with an NVIDIA T4, Tesla P4, and L4 respectively, coming in at roughly $200, $330, and $515/month respectively in the US region (after sustained usage discount). Out of this list, currently Flash Attention v2, a requirement for working with some AWQ quantized models, is only supported by NVIDIA T4. The L4 comes in with the largest amount of VRAM at 24GB per GPU, T4 has 16GB, and P4 has a mere 8GB. The L4 also has the largest number of CUDA cores at 7424, with the T4 and P4 having 2560 respectively.
If you are running a relatively small model such as a 7B parameter model like LLaMA 2 7B, starting with an NVIDIA T4 should provide real-time inference performance at an affordable price. This is quite impressive as the T4 is quite an old GPU released in 2018. We wouldn’t recommend the P4 for most purposes, as even the small models don’t have sufficient VRAM to start up on it. The L4 is a much newer GPU released in 2023, well after it became apparent that ChatGPT and generative AI would spark a new AI renaissance that would make GPUs a hotly contested commodity.
For AI model fine-tuning and training, the A100 is a much more capable GPU, available in 40GB and 80GB VRAM flavors with 6912 CUDA cores, at approximately $2680 or $3700/month respectively on Google Cloud. The GPU pricing is current as of March 2024, and subject to change by Google.
To prepare a GPU-enabled VM for running Ollama or Text Generation Inference (TGI) with GPU acceleration, there are a few steps one must take.
1) Install the NVIDIA drivers
There are two methods for installing the NVIDIA drivers on Google Cloud. One is to install the CUDA toolkit for your GPU model and OS from this list. Another is to use the automated Python script which determines the correct driver version to install. To use the automated script, the Google Cloud monitoring agent (observability) service must be temporarily disabled, so pay attention to that if you selected that checkbox when provisioning the VM.
$ curl https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-installation/main/linux/install_gpu_driver.py --output install_gpu_driver.py $ sudo python3 install_gpu_driver.py
2) Install the NVIDIA Container toolkit.
The NVIDIA Container Toolkit is what enables the Docker daemon to pass-through the host system’s GPU capabilities to processes running within a container. NVIDIA has a handy reference for enabling the runtime for Docker, as well as CRI-O and Podman for Kubernetes and Red Hat systems. Here are the most typical steps for an Ubuntu system running the Docker Engine.
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list $ sudo apt-get update $ sudo apt-get install -y nvidia-container-toolkit $ sudo nvidia-ctk runtime configure --runtime=docker $ sudo systemctl restart docker
3) Add the NVIDIA resource to your docker run command or Compose file.
Pass the –gpus all flag to the docker run command.
OR
Add the following block to your Compose service for the Ollama or TGI container.
deploy: resources: reservations: devices: - driver: nvidia count: 1 capabilities: [gpu]
This will also work for other containers which need GPU access, such as the unstructured.io embedding model, used by AI applications like Bionic-GPT for embeddings.
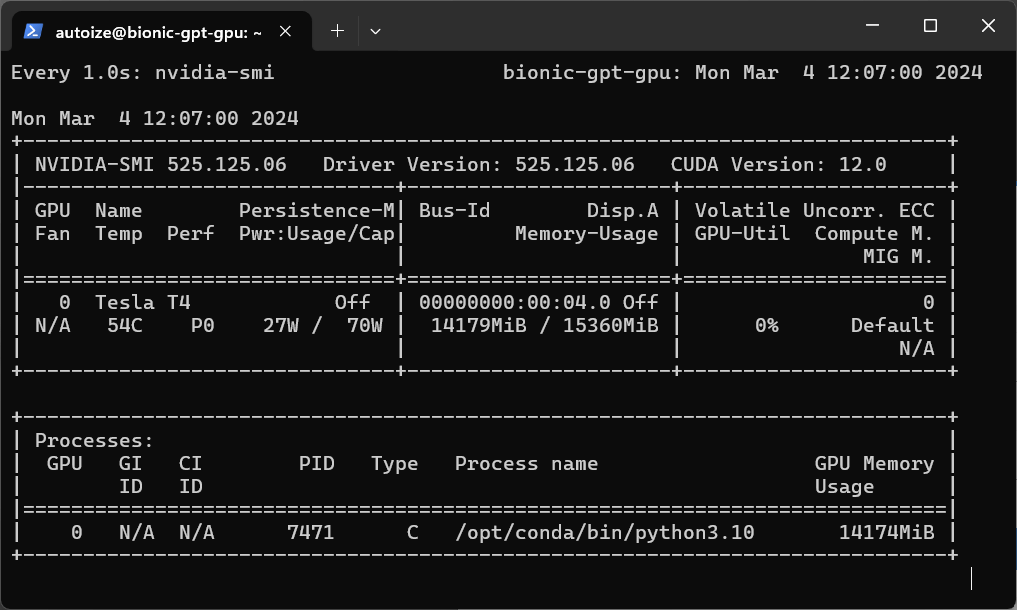
4) Monitor the utilization of the NVIDIA GPU with the nvidia-smi utility.
To monitor the temperature and % utilization of the NVIDIA GPU(s) on your system while your application, such as a ChatGPT clone, is busy at work with AI inference or embedding tasks, the watch command with the nvidia-smi utility in a terminal window works well.
$ watch -n 1 'nvidia-smi'