

AI middleware is an emerging term for the layer of the technology stack that facilitates the interfacing of AI end user applications with the Large Language Models and GPU-accelerated machines that drive them. Here are the major sub-categories of this portion of the overall AI technology stack, along with some examples of prominent projects in each category:
- AI Model Management: Ollama, LocalAI, LM Studio
- Model management tools facilitate the downloading & updating of open source community LLMs from a “model gallery” or “library” of repositories through a command line or graphical interface.
- AI Model Serving: Hugging Face TGI & TEI, vLLM, NVIDIA NIM
- Model serving refers to containerized microservices that serve up an API endpoint for calling a large language or embedding model. The containers’ lifecycles are orchestrated by an orchestrator such as Kubernetes, with GPU capabilities exposed through the NVIDIA Container Toolkit.
- AI API Proxy: LiteLLM
- An API proxy translates API calls from one format to another, as well as providing features such as load balancing, security, and cost management. This simplifies the integration of apps that use the OpenAI library by providing an OpenAI API compatible endpoint for other non-GPT models.
- AI RAG Frameworks: LangChain, LlamaIndex
- RAG frameworks assist developers in handing off prompts and responses between users, plugins, and the model, so that an AI model can draw upon additional context from external data sources to generate the highest quality response possible.
Al middleware is typically distributed as cloud native, containerized microservices, which naturally one would expect to be an ideal fit for serverless deployment. They tend to be stateless inside the container, using volumes, object storage, or external DBs to persist data between runs. But presently, one major limitation of cloud services like Azure Container Apps and Google Cloud Run prevents serving models directly using them — they do not support GPUs, which almost all AI models require to generate tokens or vector embeddings at a reasonable speed. A prominent exception to this is Cloud Run for Anthos, which is a managed service for the serverless deployment of containers on GKE that does support GPUs if the underlying compute instances in the cluster use the GPU instance types. Unlike the ordinary Cloud Run service though, Cloud Run for Anthos is not optimized for scaling down your compute instances to zero when not in use, and only really makes sense for teams that have already adopted Knative and GKE Enterprise.
For this reason, we will focus on using Cloud Run to serverlessly deploy an AI API proxy, LiteLLM, without needing to manage the underlying compute resources or container runtime. A major advantage of using Cloud Run for this use case is that containers are spun up and scaled-out automatically by GCP when your Cloud Run service, the LiteLLM proxy, is invoked by an application. The auto-scaling and ability to scale to zero (if “cold start” latency is not a concern) makes Cloud Run an incredibly cost-effective and simple to manage way to deploy an API proxy for an AI application — it is not atypical to see Cloud Run usage amounting to only several dollars a month even for production apps. LiteLLM is part of the application stack for many AI deployments for our clients, as it conveniently translates API calls from the OpenAI library to other formats that can be understood by endpoints such as Vertex AI, Amazon Bedrock, AI21, and Anthropic.
If you are already a GCP customer with a Google Cloud project, you can easily deploy the LIteLLM proxy to Cloud Run to expose virtually any AI model you wish to your applications, running anywhere. Whether you choose to run your AI models on a hosted public endpoint, a private endpoint hosted on GPU instances in a VPC, or entirely on-premise — it’s up to you. It all depends on your preferred pricing model (per-token or hourly per GPU), whether you will be running any custom models or training checkpoints, and compliance requirements (where are you allowed to process data through your AI model).
The following step-by-step example illustrates the simplest integration of LiteLLM Proxy with the gpt-3.5-turbo model running on the OpenAI API, and deploying it to a Cloud Run service. The example can be modified easily to use models deployed on other OpenAI-compatible endpoints, such as Mistral 8x7b on OctoAI, by changing the base URL. Most of the real use cases we encountered have focused on integration of LiteLLM with other AI models-as-a-service providers that are not OpenAI itself, which requires setting different environment variables and passing different arguments to the container at runtime. For more information, you may refer to the LiteLLM docs or contact our AI middleware specialists for a consultation about our AI integration services.
At the time of this writing (Apr 2024), Anthropic’s Claude 3 Opus model is seen as the most powerful LLM that can effectively compete with OpenAI’s GPT-4 at a fraction of the cost. Open source ChatGPT-style interfaces such as LibreChat support the Claude 3 models through Anthropic’s official API endpoint, or hosted AI-as-a-Service endpoints on the Amazon Bedrock service through a LiteLLM proxy container. Using LiteLLM as an AI middleware layer, we are able to offer users of the chatbot a multitude of various models including open source models like LLaMA 2 and Mixtral 8x7b, or commercial models like GPT-3.5, GPT-4 and Gemini. The open models can either reside on GPU accelerated machines that you manage yourself, or utilize hosted endpoints such as OctoAI, an AIaaS provider that specializes in providing open models as a service. By contrast, the commercial models can only be accessed through the API service of the model developers themselves, or their partners such as the Azure OpenAI Service or Claude 3 on Amazon Bedrock.
If you plan to deploy the Claude 3 Opus model through Amazon Bedrock, please get in touch with us about how you can use LiteLLM as a middleware layer in front of it easily using Google Cloud Run. This enables you to integrate any application written using the OpenAI library with the Claude AI model, even though Bedrock does not provide an OpenAI-compatible API out-of-the-box.
Using Cloud Shell, pull the LiteLLM image and push it to a private container repo.
Launch a new Cloud Shell in your GCP project, pull the LiteLLM container image from the developer’s repo, and push it to a private repository in Artifact Registry, Google’s managed container registry.
It is better to use Cloud Shell in “ephemeral” mode by launching it at the https://shell.cloud.google.com/?ephemeral=true&show=terminal link, so that the pulled image does not take up the 5 GB of storage in your home directory. If you get a “permission denied” error when pushing the image, ensure that you have authenticated to the correct project where you have sufficient IAM permissions using the gcloud config set project [PROJECT_ID] and gcloud auth configure-docker commands.
Substitute your GCP project ID in all instances where [PROJECT_ID] appears.
$ docker pull ghcr.io/berriai/litellm:main-latest $ docker tag ghcr.io/berriai/litellm:main-latest gcr.io/[PROJECT_ID]/litellm:main-latest $ docker push gcr.io/[PROJECT_ID]/litellm:main-latest
If instead of pulling from the main-latest tag of the dev’s Github Container Registry repo you prefer to build the container image yourself using the Dockerfile in the development branch of the Github repo, you may instead use the following commands.
$ git clone https://github.com/BerriAI/liteLLM && cd liteLLM $ docker build -t gcr.io/[PROJECT_ID]/litellm . $ docker push gcr.io/[PROJECT_ID]/litellm
Next, deploy a PostgreSQL database to store the table of virtual keys that applications (or developers) making API calls to the LiteLLM proxy will use to authenticate themselves. This eliminates the need to expose the model provider’s keys to your applications, simplifying key management and revocation, reducing the attack surface that would-be attackers have to steal your API keys.
It is imperative that you use the Virtual Keys feature of LiteLLM if you are deploying the proxy to Cloud Run, as otherwise anyone with knowledge of your Service URL can incur charges against your AI provider in “unauthenticated” mode.
This can be a Postgres database you manage yourself on a Compute instance, or a managed database such as Cloud SQL on GCP or Azure SQL. Azure SQL provides a very capable free tier up to 32 GB storage that you can use, even though your LiteLLM service will reside on GCP Cloud Run.
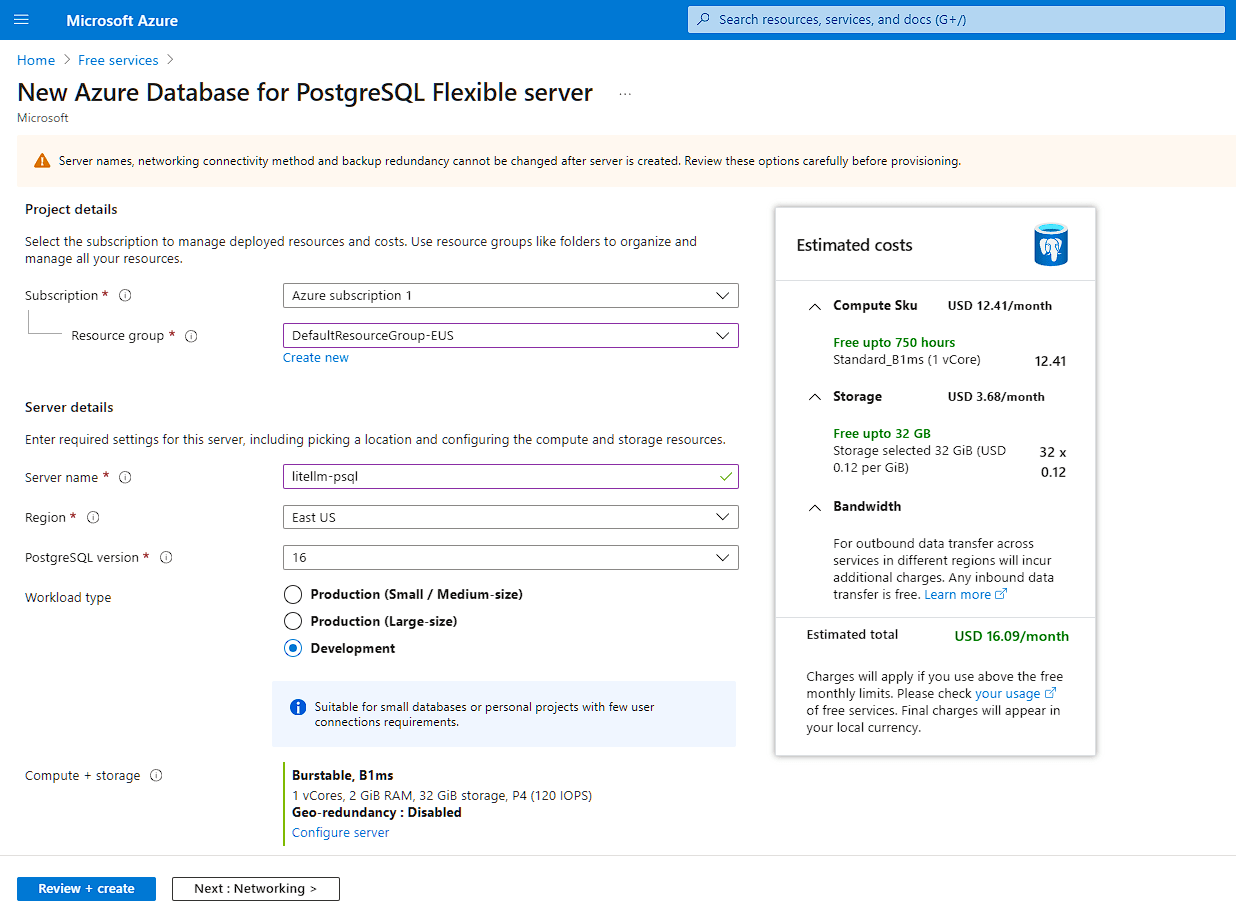
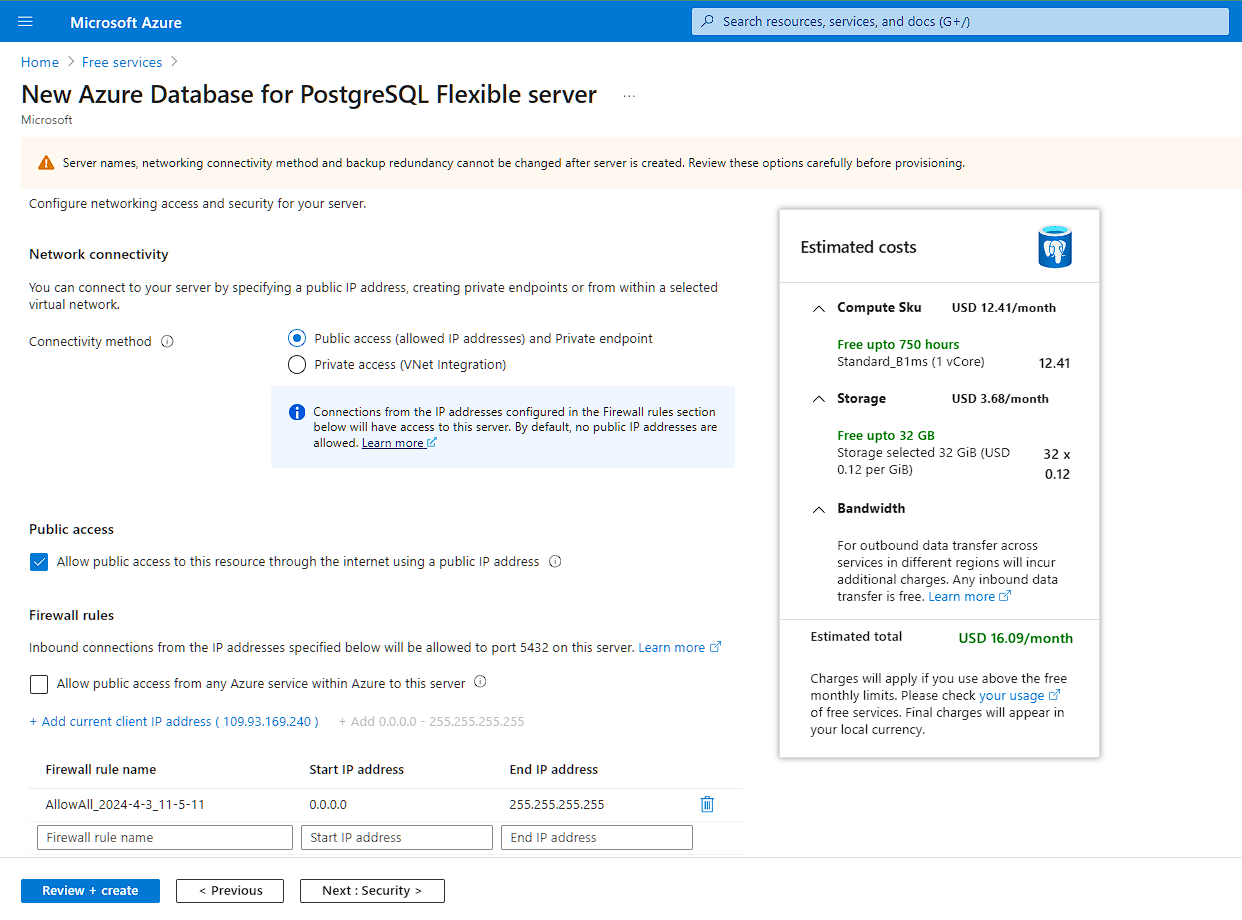
Ensure that you open up “public access” on the Postgres database from 0.0.0.0 to 255.255.255.255 as the containers for your Cloud Run service can be spun up by Google on any arbitrary IP address in GCP’s IP range. Access is authenticated by the password you set for your DB user (over TLS), so ensure it’s a strong password. For our example, we will use the DB user postgres and the DB password a$ecurepa$$w0rd.
Finally, now that your Postgres database is set up, you can proceed with deploying LiteLLM to Cloud Run. We assume you already have an API key from the AI provider that you plan to integrate with the LiteLLM proxy — in this case, OpenAI. In the example below, this key will be represented as sk-123456.
Return back to the Cloud Shell in GCP to run the following commands.
Generate a secure “master key” that you will later use to manage application-specific keys using the Virtual Keys feature of LiteLLM. Note this master key down in a safe place, as you will need it in the next step, in addition to when you generate and revoke virtual keys.
$ echo "sk-""$(openssl rand -hex 22)"
Suppose for the following example the generated master key is sk-456789.
Then, run the following command, taking care to substitute the variables with their actual values.
| Substitute the following | Example value (for Azure Database for PostgreSQL) | |
| GCP Project ID | project-id-123456 | |
| AI Provider API Key | sk-123456 | |
| DB User | <user> | postgres |
| DB Password | <password> | a$ecurepa$$w0rd |
| DB Host | <host> | litellm-psql.postgres.database.azure.com |
| DB Name | <dbname> | postgres |
| LiteLLM Master Key | sk-456789 | |
| API Base
This is the URL to your AI provider’s endpoint without the /chat/completions path |
https://api.openai.com/v1 | |
| Model | gpt-3.5-turbo |
$ gcloud run deploy litellm\ --project=project-id-123456\ --platform=managed\ --region=us-east1\ --set-env-vars="OPENAI_API_KEY=sk-123456,DATABASE_URL=postgresql://<user>:<password>@<host>/<dbname>,LITELLM_MASTER_KEY=sk-456789"\ --args="--api_base=https://api.openai.com/v1,--model=gpt-3.5-turbo,--debug"\ --image=gcr.io/project-id-123456/litellm:main-latest\ --memory=2048M\ --port=4000\ --allow-unauthenticated
If your deployment of LiteLLM to Cloud Run went successfully, you should see output similar to the below in the Cloud Shell.

LiteLLM Deployment with Cloud Run Troubleshooting
If instead you see any of the following error messages at the Cloud Shell command line or in the Log Explorer for the deployment, here are some troubleshooting tips.
-
Deployment failed ERROR: (gcloud.run.deploy) Revision 'litellm-00014-blq' is not ready and cannot serve traffic. The user-provided container failed to start and listen on the port defined provided by the PORT=8080 environment variable. Logs for this revision might contain more information.- Ensure that you have correctly set the ingress port for the Cloud Run service by passing the –port-4000 argument to the gcloud run deploy command. By default, LiteLLM listens on port 4000.
-
Error: P1013: The provided database string is invalid. invalid port number in database URL. Please refer to the documentation in https://www.prisma.io/docs/reference/database-reference/connection-urls for constructing a correct connection string. In some cases, certain characters must be escaped. Please check the string for any illegal characters.- If your Postgres database is listening on the default port 5432, then you do not need to specify port after <host> in the connection string.
-
Memory limit of 512 MiB exceeded with 513 MiB used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits- By default, Cloud Run services are deployed with a memory limit of 512 MiB. But if you are using the Virtual Keys feature of LiteLLM which relies on connecting to an external Postgres database, the container requires more memory to start up. To resolve this, pass the –memory=2048M argument to the gcloud run deploy command.
LiteLLM Proxy Usage
Now from your local development machine, you can use curl or the OpenAI library to make OpenAI-compatible API calls to your LiteLLM proxy running in Cloud Run. First, you will need to generate an application-specific API key (virtual key) using the /key/generate API call.
If my service is running at https://litellm-ihyggibjkq-ue.a.run.app I would use the following command:
$ curl 'https://litellm-ihyggibjkq-ue.a.run.app/key/generate' \ --header 'Authorization: Bearer sk-456789' \ --header 'Content-Type: application/json' \ --data-raw '{"models": ["gpt-3.5-turbo"], "metadata": {"user": "foo@autoize.com"}}'
You will receive a JSON response back containing the newly generated key in the format:
sk-abCDeFghijklMnop_qRStU
Using this virtual key, you can make text generation API calls to /chat/completions on your LiteLLM proxy, which will hand off the request to the external AI provider then return the result to your application.
$ curl https://litellm-ihyggibjkq-ue.a.run.app/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer sk-abCDeFghijklMnop_qRStU" \ -d '{ "model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "Hello world!"}], "temperature": 0.7 }'


