

Even if you have deployed an enterprise GPT platform as a dedicated workspace for your organization, it remains best practice to avoid storing unnecessary PII in your AI data infrastructure. In fact, many regulated industries & sectors such as education (FERPA), healthcare (HIPAA), and financial services (SOC II and ISO 27001) recommend or require that data be masked, or redacted when it’s not required for a particular business process or function. A common example of this is how PCI-compliant systems retain only the last four digits of a payment card once the data is transmitted to the acquiring bank. In some scenarios, for instance in the HR function, masking the name and street address of applicants in a talent management system reduces human bias when reviewing submitted resumes. Whether you are concerned about data exposure to model providers, need to prevent PII from being logged into your observability stack, or are simply aiming to make more objective business decisions, it’s worth a look at implementing a PII redaction model within your enterprise GPT system. It goes a long way toward ensuring your organization is using AI responsibly, and remaining compliant with applicable regulations. As cyber insurers wise up to the risks of AI technologies, it can be expected that self-assessment questionnaires will inquire about how insureds are limiting the exposure of confidential information to AI systems. This information would conceivably be used to underwrite coverage and price risk, determining the premium.
Organizations with robust data governance classify their data by sensitivity, and provide guidelines on which types of data may and may not be entered into AI systems. Under many jurisdictions, it is also important to label data based on whether the data subjects have given (or withheld) consent to have their data processed by AI tools. As an adjunct to policies, automatic PII masking before prompts & embeddings are sent to external AI models can be a wise decision to balance the productivity benefits of large language models (LLMs) with ever-increasing data protection requirements.
The PII redaction engine, is in fact, an AI model that pre-processes the prompts and embedding data before transmitting it to the inference service’s endpoint. In addition to blocking PII directly entered in prompts, it also sanitizes detected PII from document data found by semantic search for RAG. While inference providers such as Azure AI and Amazon Bedrock support private endpoints in your VNET or VPC, and do not share your data with the model provider, this additional layer of protection makes it feasible to roll out workplace AI tools in more sensitive settings.
The open source PII redaction library that we integrate with artificial intelligence tools such as LibreChat and Nextcloud AI Assistant is known as Microsoft Presidio. Presidio is developed and maintained by Microsoft engineers at Microsoft Open Source, but it runs in any Python 3.8 environment and is compatible with AI middleware libraries like LiteLLM that emulate the OpenAI API – the de-facto standard for developing AI applications. The Presidio classes can be included directly into your Python project, or it can be deployed behind a Flask server in a Docker container for applications in other programming languages to plug in to.
By default, Presidio ships with the SpaCY NLP model and a set of predefined recognizers that use a combination of natural language processing and regex patterns to detect a variety of PII from different jurisdictions around the world. It prevents users of the frontend application from intentionally or accidentally submitting prohibited PII data to AI models through chatbots or assistants. Instead of the restricted data itself, it is automatically replaced with a placeholder such as <PERSON>, <ORGANIZATION>, <PHONE_NUMBER>, <DATE_TIME>, or <LOCATION> before the prompt or embedding is transmitted to the AI model.


All the recognizers listed below, other than the ones labeled with “(NLP)” are based on the regex patterns for the piece of data being targeted for redaction. The NLP recognizers, such as SpaCY, Stanza, and Transformers rely on the training data, and named entity recognition (NER) techniques to determine the likelihood that a submitted token is PII.
- crypto_recognizer – Crypto Recognizer
- iban_recognizer – IBAN Recognizer
- it_fiscal_code_recognizer – Italy Fiscal Code Recognizer
- sg_uen_recognizer – Singapore UEN Recognizer
- us_driver_license_recognizer – US Driver License Recognizer
- aba_routing_recognizer – ABA Routing Recognizer
- date_recognizer – Date Recognizer
- in_aadhaar_recognizer – India Aadhaar Recognizer
- it_identity_card_recognizer – Italy Identity Card Recognizer
- spacy_recognizer – SpaCY (NLP) Recognizer
- us_itin_recognizer – US ITIN Recognizer
- au_abn_recognizer – Australia ABN Recognizer
- email_recognizer – Email Recognizer
- in_pan_recognizer – India PAN Recognizer
- it_passport_recognizer – India Passport Recognizer
- stanza_recognizer – Stanza (NLP) Recognizer
- us_passport_recognizer – US Passport Recognizer
- au_acn_recognizer – Australia ACN Recognizer
- es_nie_recognizer – Spain NIE Recognizer
- in_passport_recognizer – India Passport Recognizer
- it_vat_code – Italy VAT Code Recognizer
- transformers_recognizer – Transformers (NLP) Recognizer
- us_ssn_recognizer – US SSN Recognizer
- au_medicare_recognizer – Australia Medicare Recognizer
- es_nif_recognizer – Spain NIF Recognizer
- in_vehicle_registration_recognizer – India Vehicle Registration Recognizer
- medical_license_recognizer – Medical License Recognizer
- uk_nhs_recognizer – UK NHS Recognizer
- au_tfn_recognizer – AU TFN Recognizer
- fi_personal_identity_code_recognizer – Finland Personal Identity Code Recognizer
- in_voter_recognizer – India Voter Recognizer
- phone_recognizer – Phone Recognizer
- uk_nino_recognizer – UK NINO Recognizer
- ip_recognizer – IP Address Recognizer
- pl_pesel_recognizer – Poland PESEL Recognizer
- url_recognizer – URL Recognizer
- credit_card_recognizer – Credit Card Recognizer
- iban_patterns – IBAN Pattern Recognizer
- it_driver_license_recognizer – Italy Driver License Recognizer
- sg_fin_recognizer – Singapore FIN Recognizer
- us_bank_recognizer – US Bank Recognizer
As a relatively lightweight model, SpaCY tends to miss a percentage of ambiguous values (i.e. false negatives), such as foreign names which are less common in the US. Because NER models rely on contextual clues, a model can sometimes be uncertain whether a word is being used as a proper name or for its dictionary meaning. This is particularly true in cases where a piece of PII is not explicitly labeled as such in the context.
The false negatives can be remedied to some degree by changing the confidence threshold for flagging an item as PII, but in our experience, we have discovered that the ideal solution is to augment SpaCY with a more capable model supported by Microsoft Presidio.
One option is to use an external recognizer, such as the PII detection feature of the Azure AI Language Service (formerly Cognitive Services). The second option is to use a different local model, for which we can recommend Flair NER (on Hugging Face) for its best-in-class redaction performance. It is also possible to use both AAI service and a local model together, if PII coverage is the priority over latency & inference speed.
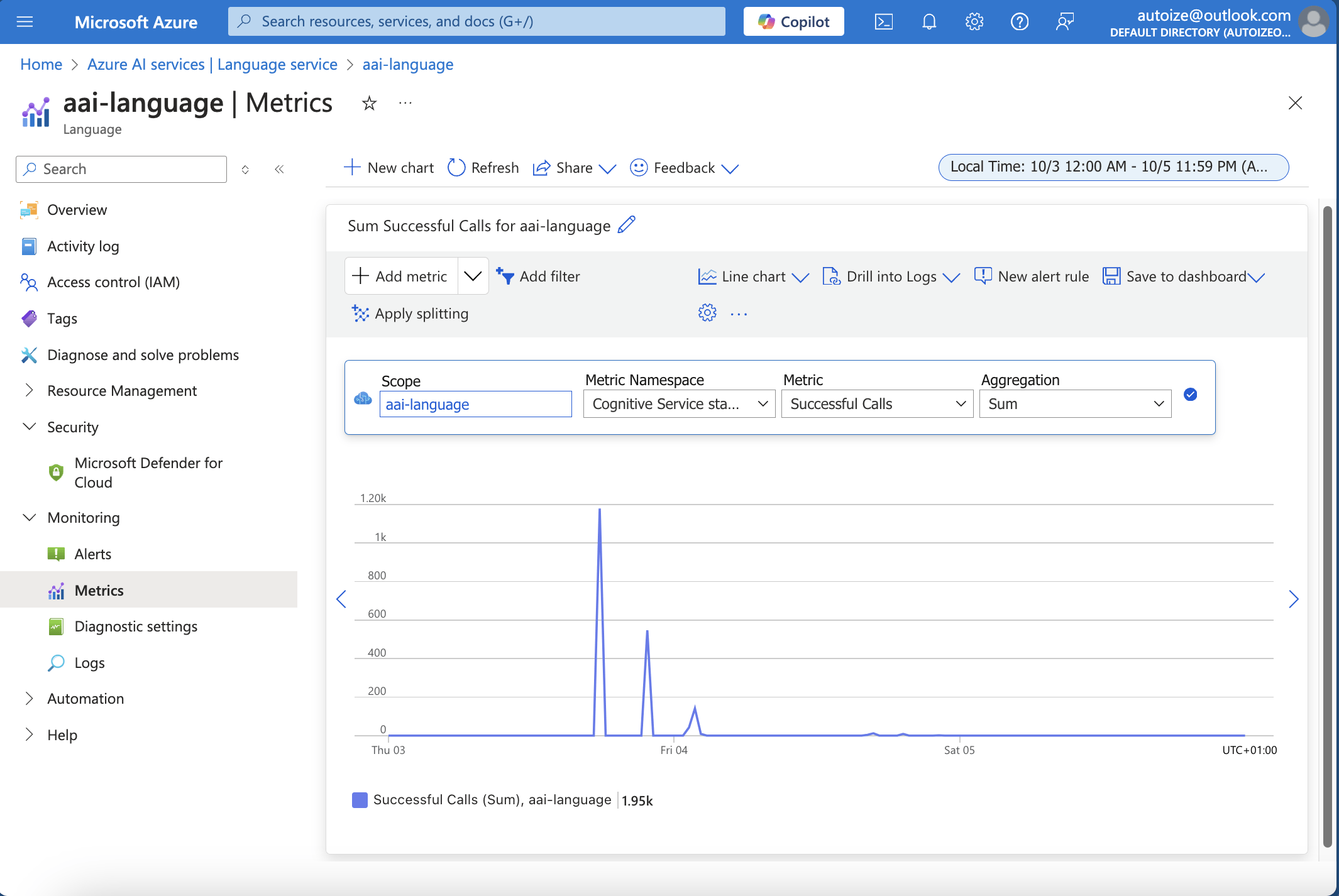
Comparatively, here are the strengths and weaknesses of using Azure AI Language Service vs. the Flair NER model with Presidio anonymizer:
| Presidio with Azure AI Language Service | Presidio with Flair NER model | |
| Deployment model | Managed API on Azure | Runs locally on your server |
| Cost | $1/1000 text records (1 text record = 1000 characters or 1 API call) | Cost of the compute resource to run the Flair NER model |
| PII coverage (detection rate) | Better PII coverage than the default Presidio model | Best PII coverage compared to the default Presidio model |
| Resource usage | Low, as the processing is offloaded to Azure | Moderate to high as processing happens locally |
| Streaming responses | Generates extremely high number of API calls per prompt (not recommended) | Supported with sufficiently powerful hardware (CUDA GPU recommended) |
| Privacy | LoggingOptOut enabled by default. All data processed within the region selected. | Highest degree of privacy as all processing happens on board your server |
In this LinkedIn article published by Nadia Privalikhina of AI Insiders, she compares the Presidio anonymizer to other PII redaction libraries such as OpaquePrompts and LLM Guard, and concludes that Presidio with the Azure AI Language or Flair NER-English-Large model provides the best coverage for PII detection.
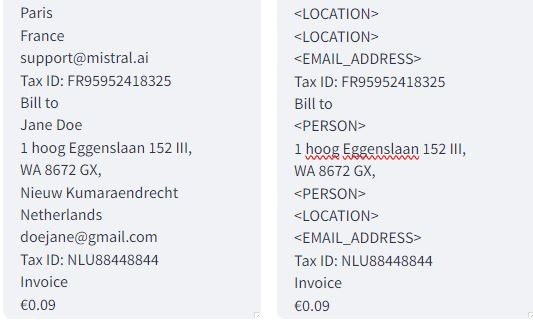


The technical process for integrating Azure AI Language or the Flair model with Microsoft Presidio requires adding the external recognizer to the default_recognizers directory of the Presidio container, then enabling the recognizer by adding it to the recognizer registry. You also need to use an AI middleware proxy such as LiteLLM to make the API call to and parse the callback from the Presidio container, then hand off the prompt to the inference endpoint.
Our specialized AI & data infrastructure consulting group can assist you with each step of customizing and integrating an enterprise GPT application for your organization. Please get in touch and we would be delighted to discuss your project and its requirements.


